
Remember me
BDS makes a decision as soon as the minimum risk criterion is met. Specifically, the algorithm terminates at the earliest stimulation time point t where at least one class's score fi surpasses the minimum risk decision boundary η. Furthermore, it is possible to establish a maximum trial length t*, after which the most probable class label is emitted (or potentially the trial is ignored and redone). The BDS procedure is outlined in Algorithm 1.

Algorithm 1. The BDS procedure.
In summary, at each stimulation time point, the dynamic stopping algorithm makes a decision. If the score is below the threshold, it is a negative decision and in case the score is above the threshold, it makes a positive decision. Hence, there are four possible outcomes corresponding to the four courses of action listed in Section 2.2:
• No winning class is detected while the score of the true class is not winning (true negative).
• No winning class is detected while the score of the true class is winning (false negative or miss).
• The winning class is detected while the score of the true class is not winning (false positive).
• The winning class is detected while the score of the true class is winning (true positive or hit).
2.3 Baseline early stopping methodsWe compared BDS with several other early stopping methods, including static and dynamic stopping techniques. Firstly, we contrasted BDS with the approach of conducting no early stopping, but instead employing a fixed trial length. We evaluated this by estimating a decoding curve for all trials and participants. The trial length could be regarded as a hyper-parameter for this method, and we assessed the accuracy achievable with each length. The trial length of 4.2 s, which uses the full trial duration, exploits all available data in the dataset, theoretically offering an upper bound on classification accuracy.
Secondly, we contrasted BDS with three static stopping methods. Each of these methods estimated a decoding curve on the training data and optimized a specific criterion to determine an optimized stopping time for all trials within a given participant. Using a 5-fold cross-validation approach on the training data, a classifier was calibrated on the training split and then tested on all validation trials ranging from 100 ms to 4.2 s in 100 ms increments.
The first static stopping method selected the stopping time at which the averaged decoding curve across folds achieved the highest accuracy for the first time. The second method chose the first instance where a predefined targeted accuracy was obtained. This targeted accuracy served as a hyper-parameter of the method. Lastly, the third method identified the stopping time at which the decoding curve achieved the highest information transfer rate (ITR).
Thirdly, we contrasted BDS with two dynamic stopping methods from previous studies: one relying on margins of classification scores (Thielen et al., 2015) and the other on a Beta distribution of the classification scores (Thielen et al., 2021).
Firstly, the margin method was a calibrated approach that considered the margin between the maximum and runner-up classification scores. During calibration, it learned a margin threshold for stimulation time points ranging from 100 ms to 4.2 s in 100 ms increments. These thresholds were learned to achieve a predefined targeted accuracy. During testing, the symbol associated with the maximum classification score was released as soon as the margin threshold was reached (Thielen et al., 2015).
Secondly, the Beta method did not require calibration. During testing, it estimated a Beta distribution based on all classification scores except the maximum one. Subsequently, it evaluated the probability that the maximum classification score did not originate from the estimated Beta distribution. If this likelihood surpassed a predefined targeted accuracy threshold, the classification was released (Thielen et al., 2021).
2.4 Analysis 2.4.1 ClassificationFor classification, we employ the “reconvolution CCA” template matching classifier (Thielen et al., 2015, 2021). Consider we have multi-channel, single-trial EEG data X ∈ ℝC×T, with C channels and T samples. To predict the label ŷ for this trial, we perform template matching as follows:
ŷ=argmaxif(w⊤X,r⊤Mi) (20)Here, w ∈ ℝC is a spatial filter, r ∈ ℝM is a temporal response vector with M samples, and Mi∈ℝM×T is a structure matrix representing the onset, duration, and overlap of each event (e.g., flashes) in the ith stimulus sequence, where i ∈ and N is the number of classes (i.e., the number of symbols in a matrix speller).
The function f represents the scoring function that calculates the similarity between the spatially filtered EEG data w⊤X and the predicted template response for the ith stimulus r⊤Mi. Typically, f is the Pearson's correlation coefficient (Thielen et al., 2015, 2021). However, in this work, we use the inner product, as BDS relies on the inner product as the similarity score.
The reconvolution CCA method requires the spatial filter w and temporal response r to be learned from labeled training data. This is achieved through canonical correlation analysis (CCA) as follows:
argmaxw,r ρ(w⊤S,r⊤D) (21)In this formulation, S ∈ ℝC×KT is a matrix consisting of K concatenated training trials, and D ∈ ℝM×KT is a matrix of stacked structure matrices that correspond to the labels of the training trials. CCA then identifies the spatial filter w and temporal response r that maximize the Pearson's correlation coefficient ρ between the spatially filtered EEG data and the predicted template responses.
2.4.2 EvaluationWe evaluated the proposed BDS method using all 108 trials from each of the 12 participants in the dataset, using 5-fold cross-validation. For each fold, 4/5 of the data served as the training set, on which the classifier was calibrated, resulting in the spatial and temporal filters necessary for classification. The parameters of BDS, including the scaling factor α, the noise standard deviation σ, the mean b1, b0 and standard deviation σ1, σ0 of the target and non-target distributions, and the decision boundary η as a function of stimulation time, were estimated from the same training data as described in Section 2.2. The remaining 1/5 of the data was used as the test set, where trials were classified according to reconvolution CCA once the stopping decision was made by BDS.
The baseline methods were evaluated using the same 5-fold cross-validation approach. For the static methods, the optimal trial length was determined using the training set in each fold. To assess whether the choice of similarity measure influences classification performance, we evaluated both the Pearson's correlation coefficient and the inner product. Among the baseline methods, the dynamic Beta stopping method does not support the inner product as a similarity measure, because its distribution range is bounded, which is not applicable to the inner product.
For each method, we varied their respective hyper-parameters to evaluate the changes in performance. The hyper-parameter for BDS was the cost ratio ζ. For the static methods, as well as the dynamic margin and Beta stopping methods, the targeted accuracy was used as the hyper-parameter.
To evaluate the performance of the early stopping methods, we considered several performance metrics. Firstly, we examined the conventional average accuracy versus average stopping time. However, since BDS aims to minimize risk rather than maximize accuracy, we also assessed performance using precision, recall, and F-score, which are relevance-based performance metrics. Precision (also known as positive predictive value) is the fraction of true positives among all the positive decisions:
precision=true positivestrue positives + false positives (22)and recall (also known as sensitivity) is the ratio between the correct detections and all the detectable instances:
recall=true positivestrue positives + false negatives (23)We also looked at specificity (i.e., true negative rate):
specificity=true negativestrue negatives + false positives (24)To compute the true/false positives/negatives, we examined all decisions made by the stopping procedures at each stimulation time point within each trial. With knowledge of the true label for each trial, we determined whether the highest similarity score at each stimulation time point corresponded to the true class. This enabled us to determine whether a positive or negative decision made by the stopping algorithm was true or false. Having the total number of true/false positive/negative decisions, we calculated precision, recall, specificity, and thereby the F-score:
F-score=2*precision*recallprecision + recall (25)When interpreting these relevance-based measures, it is crucial to consider that the number of negative decisions in a stopping task far exceeds the number of positive decisions. This discrepancy arises because, for each trial, only one positive decision is made at the stopping time point, while negative decisions are made at all stimulation time points before that.
3 ResultsFirstly, we investigated the performance of the proposed BDS method across various performance metrics. Figure 2 shows how the performance of BDS changes for each of the 12 participants in the dataset as the cost ratio between false positive and false negative errors ζ changes from 1e-10 to 1e10. The performance is evaluated using the six measures explained in Section 2.4 and averaged over the cross-validation folds (108 trials) for each participant.
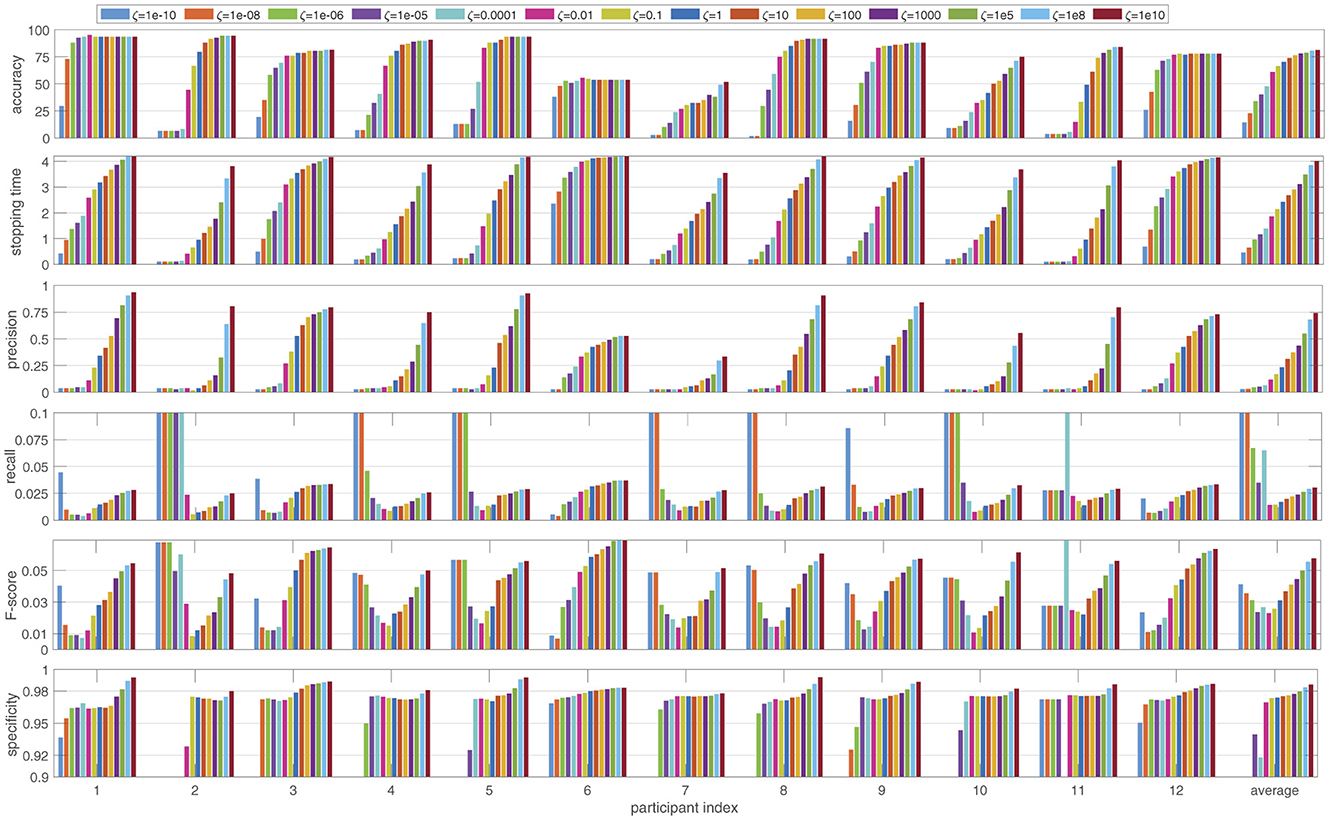
Figure 2. The performance of the Bayesian dynamic stopping averaged over the 108 trials for each participant, as the cost ratio ζ changes between 1e-10 and 1e10. The performance is measured in terms of accuracy and average stopping time as well as the relevance-based metrics precision, recall, F-score and specificity and is reported both per participant and averaged over the 12 participants.
As the cost ratio ζ increases, BDS becomes more accurate (higher accuracy) but slower (longer stopping time). The rate of these changes varies among participants. For example, for participants 1 and 6, altering the cost ratio has minimal impact on the accuracy. However, while the stopping time for participant 1 increases with a higher cost ratio, participant 6 shows much less sensitivity in stopping time.
Investigating precision, recall, specificity and F-score reveals several trends as the cost ratio ζ increases. Precision rises more sharply than accuracy, indicating that precision is highly sensitive to the cost ratio. Recall, on the other hand, does not change monotonically. For ζ < 1, recall decreases as ζ increases, whereas for ζ > 1 an increase in ζ leads to an increase in recall. A similar pattern is observed in the F-score, suggesting that due to the larger number of negative decisions, the F-score is more influenced by recall than by precision. Finally, specificity shows smaller variations compared to other metrics, but still shows an overall increase as ζ increases.
Secondly, we compared BDS with several baseline methods, including fixed, static and dynamic stopping methods, as described in Section 2.3. Figure 3 presents the results in terms of average accuracy versus average stopping time, while the hyper-parameters of each method vary.
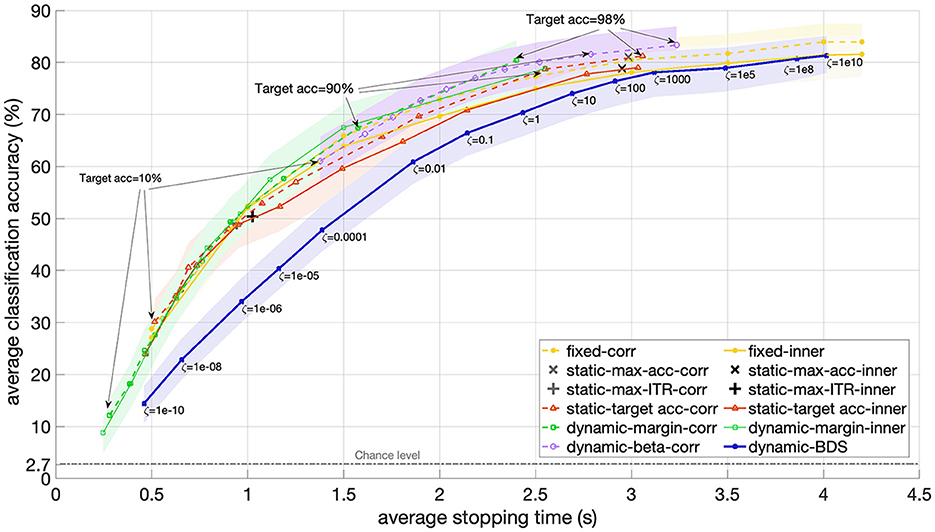
Figure 3. Accuracy versus stopping time averaged over 12 participants for BDS and static and dynamic stopping methods from the literature as the hyper-parameter of each method changes. For BDS (blue), the hyper-parameter is the cost ratio ζ ranging from 1e-10 to 1e10. For the static stopping methods with optimized accuracy (red), the margin (green), and beta (purple) dynamic stopping, the targeted accuracy varied between 10% and 98%. The static methods that maximize accuracy (gray ×) or ITR (gray +) do not have a hyper-parameter and therefore appear as one point in the figure. The performance of a fixed trial length from 0.5 s to 4.2 s is also included for reference (yellow). All but one of the baseline methods are implemented using both correlation (dashed) and inner product (solid) as the similarity score. The shaded areas indicate the 95% confidence interval.
For the fixed trial length, the hyper-parameter was the trial length, which varied between 0.5 s and 4.2 s. For the static stopping with accuracy optimization as well as dynamic stopping margin and beta, the hyper-parameter was the targeted accuracy, which ranged from 10% to 90%. The static methods that optimized accuracy or ITR did not have a hyper-parameter, hence they appear as single points in Figure 3 (+ for maximizing ITR and x for maximizing accuracy). All the baseline methods, except for dynamic beta stopping, are implemented both with correlation (dashed lines) and inner product (solid lines) as similarity scores.
As illustrated in Figure 3, using the correlation as the similarity score leads to higher performance for fixed length trials and static stopping methods when the trial duration exceeds 1 second. For the dynamic margin method, the performance appears largely independent of the similarity score, except when the targeted accuracy exceeds 80%, where the inner product results in a slightly shorter average stopping time.
Among the dynamic stopping methods, the beta stopping method achieves the highest average accuracy in the shortest average stopping time. However, the obtained accuracy often deviates from the predefined targeted accuracy. For instance, when the targeted accuracy is set to 10%, the beta stopping method still achieves an accuracy of 61%, with the average stopping time not dropping below 1.3 s.
The dynamic margin method spans the shorter time area of the plot. With a targeted accuracy of 10% it achieves an average stopping time of 240 ms and an accuracy of 8.7% accuracy (which is still higher than the theoretical chance level 2.7%). As the targeted accuracy increases, the margin method's performance varies non-linearly. For instance, at a targeted accuracy of 98%, the method reaches an average stopping time of 2.4 s and an accuracy of 80.4%. However, when the targeted accuracy is reduced to to 90%, the resulting accuracy drops to 67%.
The static stopping method with targeted accuracy and inner product as similarity score results in a static stopping time of 0.5 s and an average accuracy of 30% when the targeted accuracy is set to 10%. For a targeted accuracy of 98%, the obtained accuracy is 79% with a static stopping time of 3 s.
In summary, each of these baseline methods covers only a limited portion of the accuracy-time plane, restricting the range within which their hyper-parameters can control them. The average accuracy values obtained by these methods for similar average stopping times are not significantly different, as indicated by the overlapping 95% confidence intervals. Additionally, the targeted accuracy does not reliably predict the actual empirically obtained accuracy for many of the baseline methods.
The proposed BDS tends to result in a longer average stopping time for a similar accuracy level compared to the baseline methods. Or equally, for each average stopping time (reflecting speed), BDS yields a lower accuracy level. However, the difference in accuracy between BDS and static stopping for average stopping times longer than 1.5 s is not statistically significant, as indicated by the overlapping 95% confidence intervals (see Figure 3). Similarly, the difference in accuracy between BDS and beta stopping is not significant for average stopping times above 2.5 s. Overall, the observed differences in accuracy were anticipated because BDS is designed to minimize risk, not error rate (hence, not to maximize accuracy). To assess the performance of each method in terms of risk, it is essential to examine precision for each method.
In Figure 4, the average precision across all 12 participants is plotted against the average stopping time for BDS, as well as for the two dynamic stopping baselines, i.e., the margin and beta methods. Notably, the margin method achieves a maximum precision slightly below 0.2, and the beta method obtains its highest precision of 0.44 at an accuracy of 83.3%. Instead, BDS shows comparable precision to both the margin and beta methods for average stopping times below 1.5 s, but beyond this, BDS surpasses the margin method in precision. Additionally, when the cost ratio ζ > 1, implying a higher cost for false positive than false negatives, BDS's precision begins to outperform that of the beta method as well. These observed differences are statistically significant, indicated by the very small and non-overlapping 95% confidence intervals. This suggests that BDS excels in precision. Furthermore, BDS demonstrates the capability to increase its precision up to 0.75 by applying higher values of the cost ratio ζ.
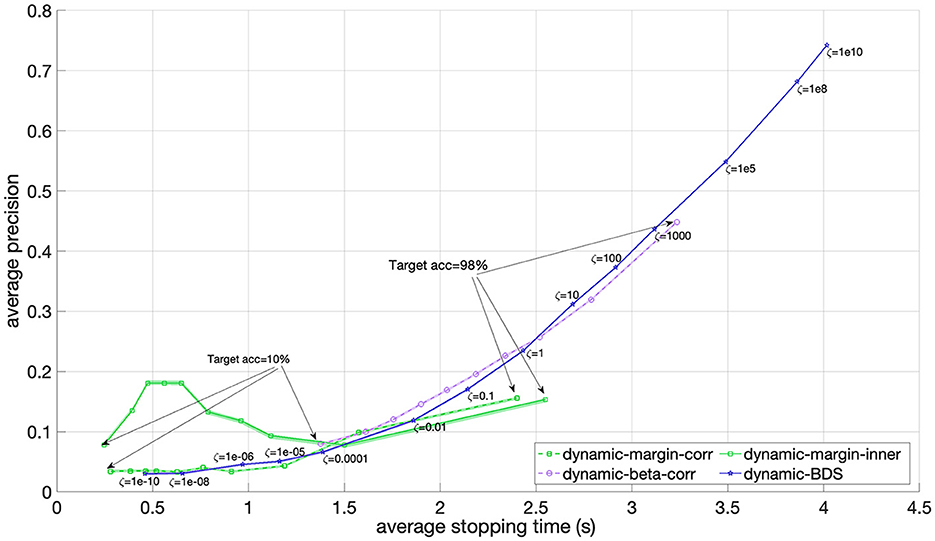
Figure 4. Precision versus stopping time averaged over 12 participants for the BDS, margin and beta dynamic stopping methods as the hyper-parameter of each method changes. For BDS (blue), the hyper-parameter is the cost ratio ζ which ranges from 1e-10 to 1e10. For the margin (green) and beta (purple) methods, the targeted accuracy ranges between 10% and 98%. The margin method is implemented using both correlation (dashed) and inner product (solid) as the similarity score. The 95% confidence interval is visualized using a shaded area, but they are in the range of 0.005 and therefore barely visible.
4 DiscussionIn this study, we proposed a model-based Bayesian dynamic stopping (BDS) method for evoked response BCIs and compared its performance with several existing static and dynamic stopping methods. The primary goal of this novel approach was to provide more control over the behavior of the stopping method, making it suitable for various BCI applications with different requirements. For example, applications sensitive to false positives, which result in miss-classifications, need a different dynamic stopping behavior compared to those where false negatives are more critical, which results in misses. We achieved a controllable precision-speed balance by assigning different cost values to each error type and minimizing the associated risk.
In general, dynamic stopping methods offer various advantages over fixed trial length and static stopping methods, making them a crucial area for exploration and improvement. With dynamic stopping, we can achieve more reliable decoding by allowing more data before making decisions, unlike static methods where decisions are made at a fixed time point regardless of the trial-specific confidence level. This adaptability is particularly beneficial given the non-stationary nature of EEG data. Dynamic stopping allows for faster classification of trials with high SNR, while granting more time for those with lower SNR. Additionally, dynamic stopping ideally facilitates the incorporation of a non-control state and asynchronous control by enabling decisions only when the certainty is sufficiently high, thereby enhancing the overall system responsiveness and user experience.
Examining the performance comparison between the baseline dynamic stopping methods and the static and fixed trial length methods (see Figure 3), it is evident that dynamic stopping methods achieve accuracy levels comparable to those of static, fixed and even optimized stopping methods for a given trial length.
While many dynamic stopping methods have been proposed for various types of evoked response BCIs, few offer inherently calibrated hyper-parameters that intuitively and effectively control the accuracy-speed balance. Additionally, many existing methods focus on optimizing metrics such as accuracy, ITR or SPM, which do not necessarily reflect user-centric performance across different applications with varying sensitivities to different error types. Our proposed method addresses this issue by providing a hyper-parameter that allows for differential treatment of error types, enabling fine-tuned control over the accuracy-speed trade-off.
Many of the existing dynamic stopping methods have one or more hyperparameters that either need to be set manually or tuned by a search for optimal performance. BDS has only one hyperparameter, the cost ratio ζ, which can also be optimized by hyperparameter search to optimize a certain performance metric. However, importantly, because the cost ratio is a very intuitive parameter, it can be set by the designer given the requirements of the application. This contrasts with, for example, the threshold value in a threshold-based stopping method that does not have any intuitive connection to the application.
We evaluated our proposed method, BDS, using an open-access c-VEP dataset including 12 participants, each with 108 trials. Performance metrics were calculated for each participant individually and then averaged across all participants.
The per-participant results show that changing the hyper-parameter ζ, which is the cost ratio between false positive and false negative errors, allows control over the accuracy and speed of BDS. However, the effect of changing the cost ratio varies among participants. Such adjustment also affects relevance-based metrics: precision, recall and specificity. When ζ > 1, implying a higher cost for false positive errors than for false negative errors, increasing ζ calls for a more precise classification, resulting in longer stopping times. Conversely, ζ < 1 implies a higher cost for false negative than for false positive errors, so decreasing ζ leads to a faster system with shorter stopping times but reduced accuracy and precision (see Figure 2).
Recall, by definition, is the complement of the false negative error rate. The low recall values in our results indicate an imbalance between negative and positive decisions. This is because each trial only involves one positive decision, which stops the trial, whereas negative decisions are made at all stimulation time points before the stopping time. When ζ > 1, increasing ζ leads to a higher number of true positives and more false negatives due to the longer waiting time. However, the increase in recall shows that the rise in true positives is larger than the increase in false negatives. Conversely, when ζ < 1, decreasing ζ reduces the number of true positives and false negatives. The increase in recall as ζ decreases indicates that false negatives decrease faster than true positives. This behavior is observed in recall for most of the participants. Because of the imbalance between positive and negative decisions and the resulting disparity between the ranges of precision and recall, the F-score tends to follow the recall pattern. Finally, the high specificity values demonstrate that the number of true negatives exceeds false positives. Consequently, the effect of changing ζ is less pronounced in specificity due to this imbalance.
We investigated the performance of BDS and the baseline methods by examining how their hyper-parameters affect accuracy and speed. An intriguing observation is that for the methods with targeted accuracy as their hyper-parameter, adjusting the targeted accuracy does change the accuracy-speed balance but does not guarantee achieving the targeted accuracy at either extreme time points. Moreover, each method spans a limited region in the accuracy-time plane, meaning that some accuracy or speed levels are unattainable for certain methods.
In contrast, the hyper-parameter of BDS allows for a wide range, from very fast and inaccurate, to very slow and accurate classifications, controllable by the cost ratio. However, for a given speed (average stopping time), the accuracy of BDS is typically lower than the other methods. Since BDS is designed to minimize risk rather than maximize accuracy, it is more appropriate to evaluate it in terms of precision.
Figure 4 compares the dynamic methods based on precision versus stopping time. The results show that BDS achieves comparable precision to the margin and beta methods within the speed levels they share. However, interestingly, BDS can achieve a much higher precision (up to 0.75) compared to the beta method's maximum achievable precision (0.32) by assigning a higher cost to false positive errors through a larger cost ratio ζ.
While the evaluation of our proposed stopping method on an offline dataset indicates the effectiveness of the BDS method in controlling the error types and its advantage in terms of relevance-based metrics, future research requires a more in-depth exploration of user experience and usability in an online setting to ensure the method's practicality in real-world applications.
It is essential to approach the results of our study on the novel proposed Bayesian dynamic stopping framework with caution and consider several important limitations. Firstly, in this study, we focused on carefully explaining the extensive math and description required for introducing our method and evaluated and compared BDS using a single c-VEP dataset, to provide empirical support for the effectiveness of the method. While BDS shows promise, its applicability to other evoked datasets such as ERP and SSVEP requires further investigation. Additionally, we believe BDS can easily be extended to other c-VEP datasets as well, generalizing beyond the specific stimulation sequences used here, because it holds no assumptions of the underlying structure in the data.
Secondly, it is worth noting that our comparison was limited to a handful of static and dynamic stopping methods. While numerous other methods exist in the literature, most of them either have a structure or make assumptions that limit them to a certain paradigm or setup. As an example of the limiting structure, the dynamic stopping method developed for SSVEP in Cecotti (2020), performs score thresholding as the basis for the stopping decision. The threshold however is defined as a function of the number of stimuli frequencies used, making the method only applicable to SSVEP paradigms. There are more threshold based stopping methods in which the threshold value is arbitrarily chosen based on eyeballing the data which makes it difficult to use them as a systematic comparison baseline (Nagel and Spüler, 2019). An example of a method with limiting assumptions, we can look at the dynamic stopping method proposed by Martínez-Cagigal et al. (2023b) for c-VEP. They assume a certain relationship between the templates that is only valid when circularly shifted codes are used. Therefore, the method is not directly applicable to all c-VEP datasets, for instance, those employing a set of Gold codes. Since adapting baseline methods to be more generally applicable is beyond the scope of this paper, we limited our choice of baseline dynamic methods to those directly applicable to the c-VEP paradigm with Gold codes. Further research is necessary to comprehensively compare stopping methods, highlighting their underlying assumptions and application scenarios. This broader exploration can provide deeper insights into the strengths and limitations of different approaches, helping researchers and practitioners make informed decisions when selecting the most appropriate stopping method for their specific BCI applications.
Thirdly, BDS relies on template responses in the classifier, which are used to estimate the target and non-target distributions. While most standard decoding approaches involve some form of template (e.g., an event-related potential), others, such as deep learning frameworks, may not explicitly contain these templates.
BDS needs to be calibrated using training data as it requires knowledge of the parameters for the target and non-target distributions. However, if all non-target classes can be assigned to a single non-target distribution, the required training data can be limited to data from one class only. This is especially true when using the reconvolution CCA method, which can predict template responses to unseen stimulation sequences. Not only does this mean that BDS requires only limited training data, but it also means that BDS can handle any number of classes. Investigating the sensitivity of BDS performance to the amount of training data and its empirical performance with a small number of classes remains to be addressed in future work.
Moreover, if a zero-training approach for BDS is desired, its parameters could potentially be learned on the fly as data comes in, due to its minimal requirements on the shape of the training dataset. Nevertheless, an open empirical question remains regarding how much data is needed for BDS to learn a robust and accurate dynamic stopping rule.
While BDS allows for spanning a wide range of accuracy/precision-speed balances, the current implementation does not permit setting a specific targeted performance. However, the model does offer the potential to predict error rates using the available distributions, thereby influencing the decision of the stopping algorithm. This can help achieve desired performance levels in terms of expected error rates (total or specific error types) or precision. Formalizing and implementing such an extension to this method is an avenue for future work.
Another potential advantage of using a model-based dynamic stopping method like BDS is its ability to incorporate prior probabilities for different classes. Although in this study we focused on the case of equal priors, the model formulation allows for using non-equal priors as well. This is especially valuable in applications where some classes are much more frequent than others, enabling decisions on high-probability classes with less confidence compared to low-probability classes. An example of such an application is a speller used for typing. There are studies that use a language model to post-process the output of a BCI speller, thereby increasing the typing accuracy and speed (Gembler and Volosyak, 2019; Gembler et al., 2019b). Our proposed model offers the potential to directly integrate the language model within the dynamic stopping method, instead of using it for error correction. Integrating such priors into the stopping method is another avenue for future work.
In conclusion, BDS provides better control over false positive and false negative errors, enabling a broader range of accuracy-speed trade-offs. Additionally, BDS achieves a much higher level of precision compared to the baseline dynamic stopping methods. The proposed model opens promising directions for future work to harvest its potential more effectively.
Data availability statementThe dataset for this study, originally recorded by Thielen et al. (2015), can be found in the Radboud Data Repository, specifically Thielen et al. (2024). An implementation of BDS can be found in PyntBCI: https://github.com/thijor/pyntbci.
Ethics statementThe studies involving humans were approved by Ethical Committee of the Faculty of Social Sciences at the Radboud University Nijmegen. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study because a previously recorded dataset was used, involving human participants from which informed consent was taken.
Author contributionsSA: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft. JT: Data curation, Formal analysis, Investigation, Methodology, Resources, Software, Supervision, Writing – original draft. PD: Conceptualization, Project administration, Supervision, Writing – review & editing.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This project has partially received funding from the international ALS association under grant agreement #387 entitled, “Brain Control for ALS Patients (ATC20610)” and from the Dutch ALS foundation under grant agreement number 18-SCH-391.
AcknowledgmentsThe authors would like to express their gratitude toward Louis ten Bosch for his guidance in the mathematical derivation of the framework and Jason Farquhar and Mojtaba Rostami Kandroodi for their valuable advice during the design and formalization of the method.
Conflict of interestPD is founder of MindAffect, a company that develops EEG-based diagnosis of perceptual functions.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesBianchi, L., Liti, C., and Piccialli, V. (2019). A new early stopping method for P300 spellers. IEEE Trans. Neural Syst. Rehab. Eng. 27, 1635–1643. doi: 10.1109/TNSRE.2019.2924080
PubMed Abstract | Crossref Full Text | Google Scholar
Castillos, K. C., Ladouce, S., Darmet, L., and Dehais, F. (2023). Burst c-VEP based BCI: Optimizing stimulus design for enhanced classification with minimal calibration data and improved user experience. Neuroimage 284:120446. doi: 10.1016/j.neuroimage.2023.120446
PubMed Abstract | Crossref Full Text | Google Scholar
Cecotti, H. (2020). Adaptive time segment analysis for steady-state visual evoked potential based brain-computer interfaces. IEEE Trans. Neural Syst. Rehab. Eng. 28, 552–560. doi: 10.1109/TNSRE.2020.2968307
PubMed Abstract | Crossref Full Text | Google Scholar
Fazel-Rezai, R., Allison, B. Z., Guger, C., Sellers, E. W., Kleih, S. C., and Kübler, A. (2012). P300 brain computer interface: current challenges and emerging trends. Front, Neuroeng. 5:14. doi: 10.3389/fneng.2012.00014
PubMed Abstract | Crossref Full Text | Google Scholar
Gembler, F., Benda, M., Saboor, A., and Volosyak, I. (2019a). “A multi-target c-VEP-based BCI speller utilizing n-gram word prediction and filter bank classification,” in 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC) (Bari: IEEE), 2719–2724.
Gembler, F., Stawicki, P., Saboor, A., and Volosyak, I. (2019b). Dynamic time window mechanism for time synchronous VEP-based BCIs-performance evaluation with a dictionary-supported BCI speller employing SSVEP and c-VEP. PLoS ONE 14:e0218177. doi: 10.1371/journal.pone.0218177
PubMed Abstract | Crossref Full Text | Google Scholar
Gembler, F., and Volosyak, I. (2019). A novel dictionary-driven mental spelling application based on code-modulated visual evoked potentials. Computers 8:33. doi: 10.3390/computers8020033
Crossref Full Text | Google Scholar
Gembler, F. W., Benda, M., Rezeika, A., Stawicki, P. R., and Volosyak, I. (2020). Asynchronous c-VEP communication tools-efficiency comparison of low-target, multi-target and dictionary-assisted BCI spellers. Sci. Rep. 10:17064. doi: 10.1038/s41598-020-74143-4
PubMed Abstract | Crossref Full Text | Google Scholar
Gold, R. (1967). Optimal binary sequences for spread spectrum multiplexing. IEEE Trans. Inform. Theory 13, 619–621. doi: 10.1109/TIT.1967.1054048
Crossref Full Text | Google Scholar
Höhne, J., Schreuder, M., Blankertz, B., and Tangermann, M. (2010). “Two-dimensional auditory P300 speller with predictive text system,” in 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology (Buenos Aires: IEEE), 4185–4188.
Jin, J., Allison, B. Z., Sellers, E. W., Brunner, C., Horki, P., Wang, X., et al. (2011). An adaptive P300-based control system. J. Neural Eng. 8:036006. doi: 10.1088/1741-2560/8/3/036006
PubMed Abstract | Crossref Full Text | Google Scholar
Lenhardt, A., Kaper, M., and Ritter, H. J. (2008). An adaptive P300-based online brain-computer interface. IEEE Trans. Neural Syst. Rehab. Eng. 16, 121–130. doi: 10.1109/TNSRE.2007.912816
PubMed Abstract | Crossref Full Text | Google Scholar
Liu, T., Goldberg, L., Gao, S., and Hong, B. (2010). An online brain-computer interface using non-flashing visual evoked potentials. J. Neural Eng. 7:036003. doi: 10.1088/1741-2560/7/3/036003
PubMed Abstract | Crossref Full Text | Google Scholar
Martínez-Cagigal, V., Santamaría-Vázquez, E., and Hornero, R. (2023a). “Toward early stopping detection for non-binary c-VEP-based BCIs: A pilot study,” in International Work-Conference on Artificial Neural Networks (Cham: Springer), 580–590.
Martínez-Cagigal, V., Santamaría-Vázquez, E., Pérez-Velasco, S., Marcos-Martínez, D., Moreno-Calderón, S., and Hornero, R. (2023b). “Nonparametric early stopping detection for c-VEP-based brain-computer interfaces: A pilot study,” in 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) (Sydney: IEEE), 1–4.
PubMed Abstract | Google Scholar
Martínez-Cagigal, V., Thielen, J., Santamaria-Vazquez, E., Pérez-Velasco, S., Desain, P., and Hornero, R. (2021). Brain-computer interfaces based on code-modulated visual evoked potentials (c-VEP): a literature review. J. Neural Eng. 18:061002. doi: 10.1088/1741-2552/ac38cf
PubMed Abstract | Crossref Full Text | Google Scholar
Riechmann, H., Finke, A., and Ritter, H. (2015). Using a cVEP-based brain-computer interface to control a virtual agent. IEEE Trans. Neural Syst. Rehab. Eng. 24, 692–699. doi: 10.1109/TNSRE.2015.2490621
Comments (0)