Project initiation and management
This project was initiated by team members at CAMH and KSL. The research team includes experienced health data and computer scientist-engineers plus library and information scientists familiar with the health and healthcare domains. Over more than three years, with some intermittency due to the COVID-19 global pandemic, the research team met many times via online video conference to discuss and work on the design, development, and trial demonstration of the planned ETL pipeline for enriching CAMH's patient data knowledge graph. CAMH team members took the lead on software development for the ETL pipeline. KSL team members took the lead on metadata development and HL7 FHIR RDF Library, Observation, and Provenance data resource conformance testing. Project documentation was created and stored either in the Google Docs platform at U-M or in an instance of Confluence made available to the project by CAMH.
Technical methods overview
This study utilized a number of technical methods. First, we leveraged existing knowledge graph technology. Second, we did formal data modeling to determine the information required to trace and document semantic data enrichment. Third, we adopted and validated relevant HL7 FHIR RDF data resource types. Fourth, we developed and packaged an example pure function with a corresponding API mechanism and metadata about the function. Fifth, we developed and tested an ETL pipeline for semantic data enrichment by leveraging the prior four efforts.
Knowledge graph availability via CAMH
Throughout the project, CAMH provided access to development and production instances of its Knowledge Graph loaded with patient data. CAMH's Knowledge Graph integrates multimodal data including: Electronic Health Record data, patient questionnaire responses from a local instance of REDCap, interpretations of neuroimaging results, laboratory observations, plus sleep, fitness and other biometric data. All of the patient data in the CAMH Knowledge Graph are represented using HL7 FHIR resource types except for the neuroimaging results data, which are represented in the graph using the Neuroimaging Data Model ontology (NIDM). The CAMH Knowledge Graph takes a significant step towards providing a self-serve data platform for mental health researcher [16].
Preliminary work to outline the information space of interest
We began by examining information needed to trace pure functions and their use to enrich patient data in knowledge graphs. This work included several rounds of data resource modeling.
We started by outlining the information space of interest and developing our own"homegrown"RDF data resource models based on earlier releases of KOIO (1.0 and 2.0) and on our previous work to identify 13 categories of metadata relevant for describing pure functions [22].
At the outset, to guide and document our iterative data resource modeling efforts, we collaboratively developed a set of competency questions. Our intent was that the data resources for tracing and documenting pure functions and their use would contain answers for each competency question. We borrowed the method of using competency questions from the field of ontology development, where Competency Question-driven Ontology Authoring has been previously described [28]. As we proceeded in this work, our data resource modeling drew on concepts and relationships from two other relevant ontologies: the Function Ontology (FnO) [29] and the Provenance Ontology (PROV-O) [30].
As a proof of concept using our own homegrown data resource models, we manually created test instances of RDF data resources serialized in JSON-LD. These test data resources were loaded into a Knowledge Graph development environment. Once loaded, we used SPARQL queries to produce answers to the competency questions we developed.
Adoption of HL7 FHIR RDF data resource types
After outlining the information space of interest, we learned that the HL7 and W3C Semantic Web Health Care and Life Sciences communities had, as part of the 5th Release of FHIR, developed common, openly available semantic RDF data models for each FHIR data resource type [31]. We used our competency questions to determine whether the combined content of the HL7 FHIR RDF Library, Provenance, and Observation data resource types was sufficient for our purposes [31]. Finding that the content of these three HL7 FHIR RDF data resource types was sufficient, we set aside our homegrown data resource models. Adopting HL7 FHIR RDF data resource types provided an opportunity to demonstrate that RDF generated by a semantic patient data enrichment ETL pipeline can conform to an openly available data resource standard for describing pure functions and computations resulting from using them.
HL7 FHIR RDF data resource validation using ShEx.js
Adopting HL7 FHIR RDF allowed us to use Shape Expressions (ShEx) to programmatically validate instances of FHIR RDF data resources [32, 33]. This validation focuses on the structure that HL7 resources must have. With technical support from the HL7 FHIR RDF community, we stood up a virtual server, loaded it with the ShEx.js tool [33], and performed validation tests on the FHIR RDF Obervation and Provenance data resource types produced by the ETL pipeline. (The FHIR RDF Library data resource type is not produced by the ETL pipeline and was not validated.) Validation using ShEx.js initially indicated the presence of several errors. After correcting these errors, additional validation tests were done until conformance with the HL7 FHIR RDF standard was achieved. The ETL pipeline software was then developed to produce conformant HL7 FHIR RDF Observation and Provenance resources. More information and relevant files can be found at: https://github.com/kgrid/fhir-rdf-validation.
Example pure function used
As an example drawn from the domain of mental health for this study, KSL team members implemented a pure function in Python for computing and interpreting a total Patient Health Questionnaire (PHQ-9) score and its standard interpretation from answers to the questionnaire provided by individual patients [34]. PHQ-9 scores are a common measure used to screen for severity of depressive symptoms [35].
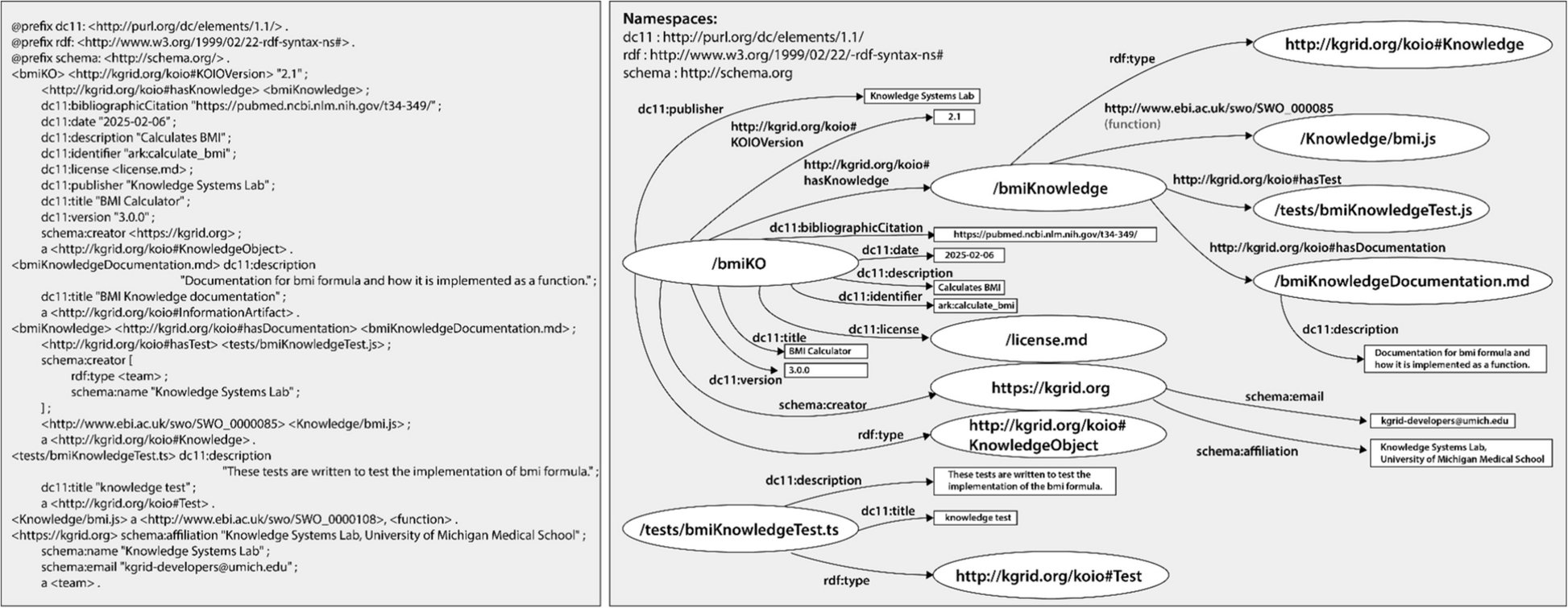
The PHQ-9 pure function exists outside of the CAMH knowledge graph where it can also be accessed by other applications through a corresponding RESTful API service. The pure function accepts the individual numeric results from the nine items comprising the PHQ-9 as its input parameters. It simply computes the total PHQ-9 score and provides an interpretation of that total score. A file with technical metadata about the origin and characteristics of the PHQ-9 pure function was also developed. These metadata were later reformatted to conform to the HL7 FHIR RDF Library data resource type specification for describing software libraries but not validated using ShEx.js. At CAMH, a software script was developed to load HL7 FHIR RDF Library metadata from the Knowledge Object into the CAMH Knowledge Graph. This script exists outside of the ETL pipeline because it only needs to run once to load and record metadata about each pure function. This script can be run on an ad-hoc basis whenever a new pure function is to be used for semantic data enrichment at CAMH.
Development of the ETL pipeline using Apache NiFi and python code
To establish the ETL pipeline and complete the technical work for this project, several existing technologies were used. When building the ETL pipeline, Apache NiFi [36] was leveraged for its ability to automate the flow of data between existing software systems. CAMH already used Apache NiFi to routinely check REDCap for new PHQ-9 responses. At CAMH, whenever new PHQ-9 responses are detected, Apache NiFi inserts them into the CAMH knowledge graph as a PHQ-9 response data object. We used Apache NiFi as a tool for implementing the ETL pipeline.
In our case, the CAMH Knowledge Graph emits Server-Sent Events (SSEs) when data is inserted, updated, or deleted. In our ETL pipeline implementation, Apache NiFi was configured to monitor these SSEs specifically for PHQ-9 responses being added to the graph. Upon detecting such an event, Apache NiFi first retrieves new PHQ-9 responses for a patient from the graph and then transmits these responses via an API request to the pure function for computation.
Each time new PHQ-9 scoring and interpretation computations are made, the ETL pipeline then produces a single new conformant HL7 FHIR RDF Observation resource representing the new computations and a corresponding single new conformant HL7 FHIR RDF Provenance resource with semantic information describing how each computation came about and linking to the specifics of the pure function used to compute it.
Testing the data enrichment ETL pipeline
Manual tests were performed at each step in the pipeline to confirm that the pipeline functioned properly. Because Blue Brain Nexus will accept essentially any RDF, to confirm that the data was inserted correctly with the expected RDF data structures, SPARQL queries were performed. Blue Brain Nexus supports conformant SPARQL queries and provides its users with immediate query results.








Comments (0)