
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Remember me
With high-resolution anatomical and functional imaging capabilities, superior soft-tissue contrast, and zero ionizing radiation, three-dimensional (3D) magnetic resonance imaging (MRI) has become indispensable in medical diagnosis and treatment (Wagner and Conti 1991, Schmidt and Payne 2015). However, the inherently slow acquisition of fully-sampled k-space data limits its applicability in time-sensitive clinical scenarios—for example, motion-resolved imaging and real-time image-guided applications (Corradini et al 2019, Talanki et al 2022, Cruz et al 2023). To accelerate acquisition, MR imaging often resorts to undersampled k-space data. This undersampling violates the Nyquist–Shannon sampling criterion, frequently resulting in aliasing artifacts in the reconstructed images (Ravishankar and Bresler 2010, Knoll et al 2020, Wang et al 2021). Although various reconstruction methods, such as compressed sensing (Lustig et al 2007, Geethanath et al 2013), dictionary learning (Ravishankar and Bresler 2010, Zhan et al 2015), and deep learning-based techniques (Liu et al 2018, Wang et al 2020, 2021), have been proposed to mitigate artifacts like blurriness and ghosting, rapidly and accurately restoring anatomically faithful images from sparse k-space data remains a challenge.
Instead of relying on reconstruction algorithms to recover images from undersampled k-space data, deformable image registration leverages deformation vector fields (DVFs) to warp a fully-sampled prior image, enabling the estimation of high-quality images that are consistent with the undersampled measurements (Qin et al 2019, Han et al 2022). This approach is particularly advantageous in workflows such as image-guided radiotherapy (Rivaz et al 2014, Rigaud et al 2019), where fully-sampled pre-treatment reference images can be leveraged to enhance image quality and anatomical consistency without requiring full acquisitions at each time. Several studies have explored this paradigm to improve MR imaging quality. Stemkens et al proposed a model-based motion estimation approach (2016) that employed a principal component analysis (PCA)-based motion model to estimate 3D DVFs from 2D MRIs. These DVFs were subsequently used to deform a prior 3D image and estimate motion-resolved 3D MR images. Shao et al proposed KS-RegNet (2022), a deep learning model in which the deformation-related data fidelity loss was evaluated directly in the k-space domain using an unsupervised training scheme. The model achieved competitive registration performance without relying on ‘ground-truth’ DVF labels. Ghoul et al proposed LAPANet (2024), a self-supervised learning framework designed to estimate deformable motion from undersampled k-space data. By combining local all-pass motion modeling with Transformer-based attention mechanisms, LAPANet yielded enhanced accuracy compared to both conventional and deep learning-based registration methods. These studies demonstrate the potential of deformable image registration in estimating high-quality images from undersampled k-space data. Nevertheless, in capturing fine-scale deformations, existing feed-forward learning-based registration frameworks often lack flexibility and generalizability when applied to diverse subjects with potential distribution shifts, leading to compromised accuracy (Hansen and Heinrich 2021).
Coordinate-based implicit neural representations (INRs) have recently been employed for deformable image registration (Wolterink et al 2022, Byra et al 2023, van Harten et al 2024). In this paradigm, a lightweight neural network is trained to approximate the DVFs by mapping input spatial coordinates to their corresponding displacement vectors, based on a loss function defined on image similarity metrics. The case-specific optimization nature of INR-based learning matches that of conventional iterative registration algorithms, rendering it robust to inter-case variability (Sitzmann et al 2020, Xu et al 2023). A range of INRs have been proposed, such as cycle-consistent INR (Van Harten et al 2023), spline-enhanced INR (Sideri-Lampretsa et al 2024), INR with neural velocity field (Han et al 2023), and geometry-informed INR (van Harten et al 2024), to enforce cycle-consistency loss, promote smooth deformations, and integrate structural priors in deformable image registration. Compared to traditional optimization-based methods, INRs achieve fast convergence through stochastic gradient descent. It also offers a continuous and resolution-independent formulation of deformation, enabling accurate modeling of complex anatomical motion. In contrast to deep learning-based models, INRs are more lightweight and not dependent on large training datasets (Grattarola and Vandergheynst 2022, Khan and Fang 2022, Gielisse and van Gemert 2025), as they can be trained on each case via ‘one-shot’ learning. Despite these advantages, optimizing INRs from scratch for each new case during inference inevitably faces a trade-off between computational efficiency and representation capacity, making them difficult to deploy in time-sensitive clinical workflows (Molaei et al 2023). Moreover, the limited representation capacity of shallow MLPs may hinder the capture of fine anatomical details and constrain the registration accuracy.
To accelerate inference and boost the registration accuracy of INRs, recent studies have explored meta-learning approaches that learn generalizable initialization parameters across multiple patients for the INRs (Lee et al 2021, Chen and Wang 2022, van Harten et al 2024, Yang et al 2025). By accumulating and transferring knowledge from multiple patient registration tasks, meta-learning enabled the INRs to rapidly adapt to new case-specific data with only a few optimization steps. Van Harten et al proposed REINDIR (2024), a meta-learning framework that combined an image encoder with a population-based INR template, where the image embedding output of the image encoder will modulate the INR template to specialize it for a test image pair. This specialization provided a better initialization of INRs for the subsequent optimization process. Another strategy for enhancing the performance of INRs involves incorporating cohort-level anatomical priors from a pre-trained population-based registration model into the model optimization process (Han et al 2023). For example, Qian et al proposed a hybrid population-based and patient-specific framework for deformation-driven cone-beam CT estimation (2025), where a pre-trained, population-based deep learning network was used to generate reference DVFs to guide the INR optimization at test time. By leveraging population-informed priors, this approach alleviates the inherent trade-off between optimization efficiency and registration accuracy in patient-specific 2D–3D deformable image registration.
To address the limitation of slow acquisition in time-sensitive clinical scenarios and enable accurate volumetric MRI for real-time image-guided applications such as motion compensation and treatment guidance in adaptive radiotherapy, we propose cMeta-INR, a cohort-informed meta-learning framework designed to boost INRs. This framework incorporates cohort-level priors as regularizations into the meta-learning process to optimize an INR template, thereby enhancing INR registration accuracy and facilitating rapid adaptation to new patients, enabling real-time volumetric MRI during treatments to guide motion-aware adaptive radiotherapy. In our approach, a token-aware modulator was designed to capture contextual information from the to-be-registered image pair, which was then used to generate structured modulation coefficients for modulating the INR template. Meanwhile, population-level DVFs and embeddings, derived from a pre-trained, deeper registration network (KS-RegNet) (Shao et al 2022), were employed to guide the meta-learning of the INR template. In general, our meta-learning mechanism was cohort-based, utilizing a population dataset for training, while test-time inference was performed via case-specific adaptation/optimization. During test-time adaptation, the INR was initialized from the learned INR template and rapidly fine-tuned on new, highly undersampled k-space data using four loss functions: deformation discrepancy between KS-RegNet- and INR-predicted DVFs, k-space fidelity between the deformed source volume and the target image, embedding similarity between the deformed source volume and the target image, and DVF smoothness regularization. The primary contributions of this study are summarized as follows:
1)
A token-aware modulator was developed to generate structured modulation coefficients, enabling fine-grained modulation of the INR template.
2)
The proposed cohort-informed meta-learning framework exploited population-level deformation priors and embeddings to guide the meta-learning of an INR template, facilitating rapid and accurate patient-specific, registration-driven 3D MRI estimation from highly undersampled k-space data during the test time.
3)
By integrating deformation discrepancy, k-space fidelity, embedding similarity, and smoothness regularization into both meta-training and test-time adaptation, cMeta-INR achieved superior registration accuracy with minimal test-time optimization for specific test subjects.
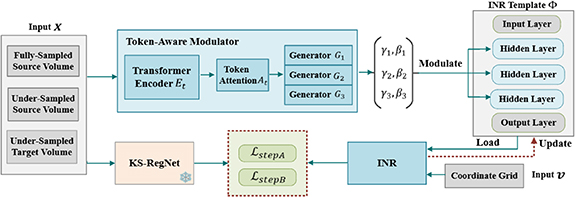
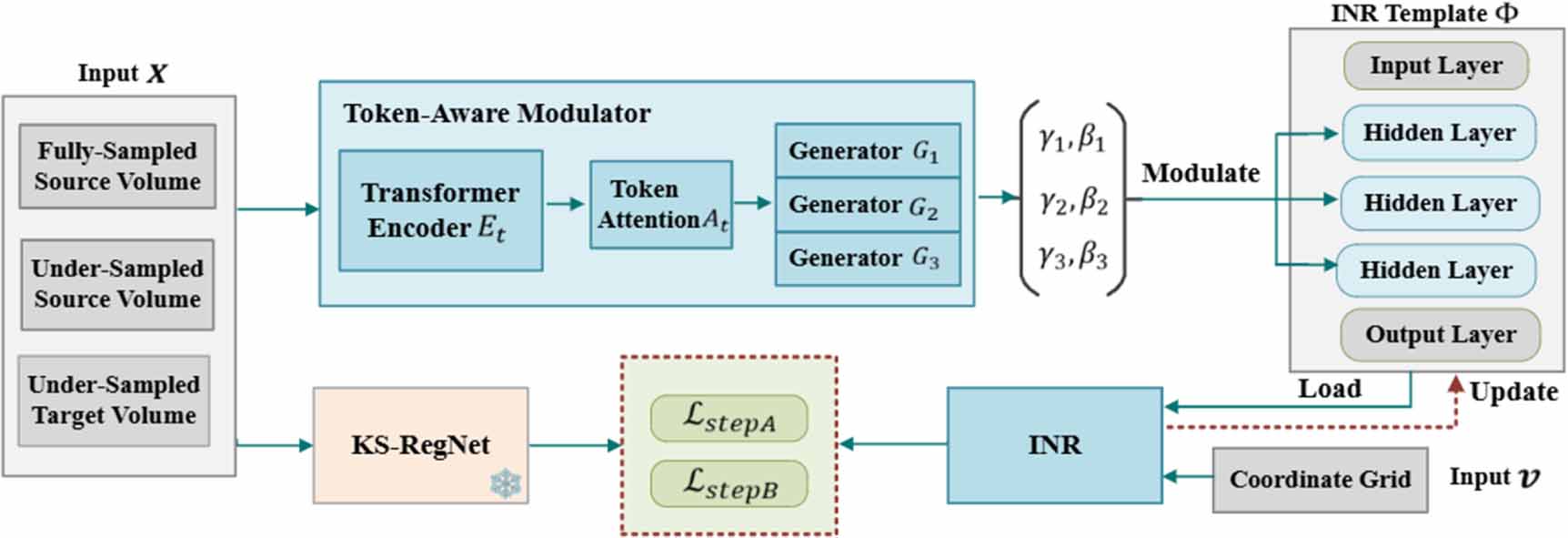
To accelerate the optimization of INRs for patient-specific deformable image registration, we proposed cMeta-INR: a cohort-informed meta-learning framework designed to enhance the representation capacity and enable faster convergence of INRs for new cases. The overall algorithm comprised two key stages: cohort-informed meta-learning (figure 1), which optimized a generalized INR template, and patient-specific adaptation (figure 3), where the INR inherited the learned template and was further fine-tuned to fit new patient data.
Figure 1. Overview of the cohort-informed meta-learning framework for learning the INR template 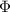 . The token-aware modulator generates the modulation coefficients (
. The token-aware modulator generates the modulation coefficients (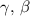 ) to adjust the hidden layers of the INR template. The pre-trained KS-RegNet (frozen) predicts the DVFs used to optimize the INR in step A, with the loss
) to adjust the hidden layers of the INR template. The pre-trained KS-RegNet (frozen) predicts the DVFs used to optimize the INR in step A, with the loss 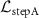 . During the meta-learning process, new training data are continuously fed into the corresponding inputs of the model, which inherits/loads the existing INR template and updates it through a two-step optimization scheme using
. During the meta-learning process, new training data are continuously fed into the corresponding inputs of the model, which inherits/loads the existing INR template and updates it through a two-step optimization scheme using 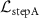 and
and 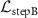 .
.
Download figure:
Standard image High-resolution image 2.1. Cohort-informed meta-learningSince training an INR from scratch was computationally intensive for test-time optimization of 3D DVFs, meta-learning mechanisms such as Reptile (Nichol et al 2018) and REINDIR (van Harten et al 2024) were proposed. In this paradigm, the meta-learning model enables INRs to acquire a generalizable, initial template which is then iteratively updated by taking a few small steps toward the task-specific optimum, allowing rapid adaptation to new patient data. However, due to the lack of prior information and the shallow network structure, existing meta-learning-based INR approaches still struggle with adaptability and generalization to unseen cases, particularly when meta-training data is limited (Yao et al 2021). To address these challenges, we proposed a cohort-informed meta-learning, as shown in figure 1, it was guided by population-level deformation priors and embeddings obtained from a pre-trained, deeper registration network. Moreover, we designed a token-aware modulator that enabled fine-grained knowledge extraction by generating structured modulation coefficients to guide the INR optimization.
Following a similar training strategy to KS-RegNet (Shao et al 2022), the raw input data for our meta-learning framework comprised a fully-sampled prior source image 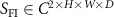 (2 channels for the real and imaginary parts) and on-board undersampled k-space data
(2 channels for the real and imaginary parts) and on-board undersampled k-space data 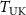 (target). To preprocess and align these data for model input, the target k-space data were reconstructed into spatial-domain images using the inverse non-uniform fast Fourier transform (NUFFT) (Muckley et al 2020), resulting in a complex-valued, undersampled target image
(target). To preprocess and align these data for model input, the target k-space data were reconstructed into spatial-domain images using the inverse non-uniform fast Fourier transform (NUFFT) (Muckley et al 2020), resulting in a complex-valued, undersampled target image 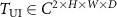 . In addition, following the same logic of the previous KS-RegNet study (Shao et al 2022), the fully-sampled source image
. In addition, following the same logic of the previous KS-RegNet study (Shao et al 2022), the fully-sampled source image 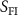 was intentionally projected into undersampled k-space data
was intentionally projected into undersampled k-space data 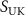 by applying NUFFT with the same radial readout trajectory as the target acquisition (
by applying NUFFT with the same radial readout trajectory as the target acquisition (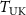 ). To perceive undersampling artifacts matching those of
). To perceive undersampling artifacts matching those of 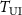 , the resulting k-space data
, the resulting k-space data 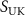 was reconstructed via inverse NUFFT to obtain an undersampled source image
was reconstructed via inverse NUFFT to obtain an undersampled source image 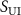
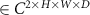 , which served as an additional input. The final input to the model consisted of the concatenation of the real and imaginary parts of the three complex-valued images X
, which served as an additional input. The final input to the model consisted of the concatenation of the real and imaginary parts of the three complex-valued images X 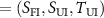 , resulting in a six-channel input
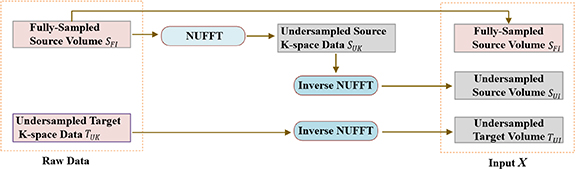
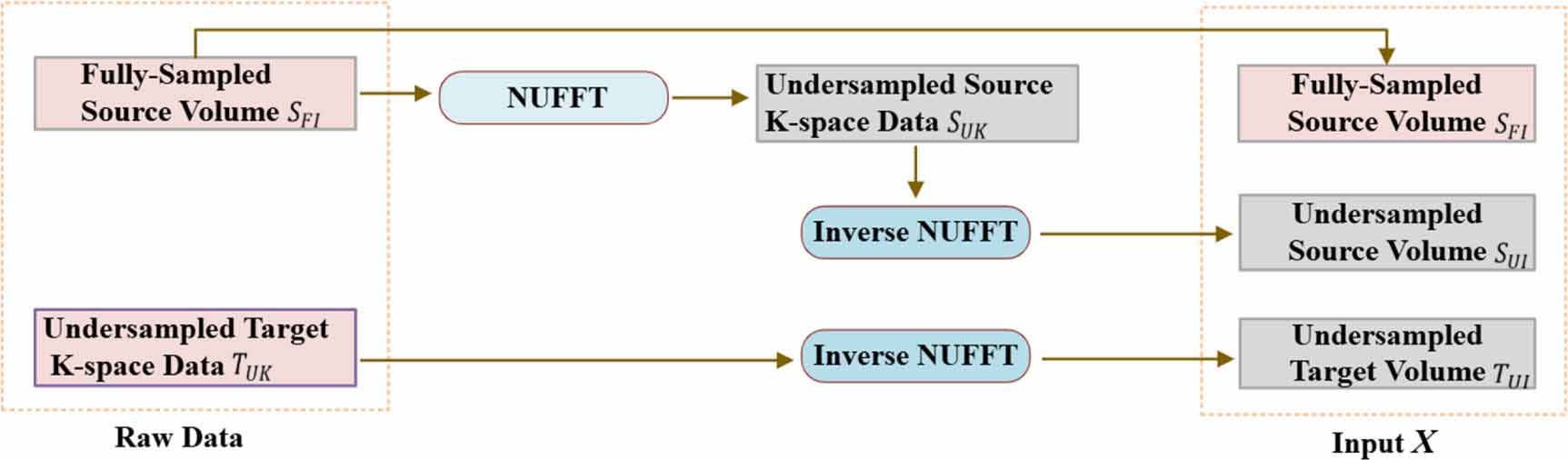
, resulting in a six-channel input 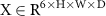 . The overall input preprocessing workflow for generating the model input is illustrated in figure 2.
. The overall input preprocessing workflow for generating the model input is illustrated in figure 2.
Figure 2. Overview of the input preprocessing pipeline. It converts the two original/raw data 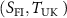 into three input volumes (
into three input volumes (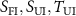 ). Specifically, the fully sampled source volume
). Specifically, the fully sampled source volume 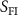 is first transformed into the undersampled source k-space data
is first transformed into the undersampled source k-space data 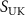 , followed by an inverse NUFFT to obtain the undersampled source volume
, followed by an inverse NUFFT to obtain the undersampled source volume 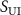 . The undersampled target k-space data
. The undersampled target k-space data 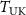 is reconstructed into the undersampled target volume
is reconstructed into the undersampled target volume 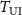 via inverse NUFFT.
via inverse NUFFT.
Download figure:
Standard image High-resolution imageAs shown in figure 1, the token-aware modulator, integrated within our cMeta-INR framework, consists of three components: a transformer encoder 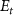 that extracts contextual tokens from the inputs X; a token attention layer
that extracts contextual tokens from the inputs X; a token attention layer 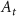 that functionally decouples the extracted tokens to focus on modulation-relevant information; and three modulation coefficient generators
that functionally decouples the extracted tokens to focus on modulation-relevant information; and three modulation coefficient generators 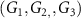 that translate the attentional tokens into structured, layer-wise modulation parameters
that translate the attentional tokens into structured, layer-wise modulation parameters 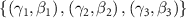 . The INR template is defined as
. The INR template is defined as 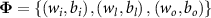 , where i, l
, where i, l 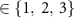 , and o indicate the input, hidden (three), and output layers, respectively.
, and o indicate the input, hidden (three), and output layers, respectively. 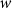 represents the neuron weightings and
represents the neuron weightings and 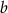 denotes the bias. In our method, only the hidden layers were modulated. The modulation of the INR template is operated by:
denotes the bias. In our method, only the hidden layers were modulated. The modulation of the INR template is operated by:
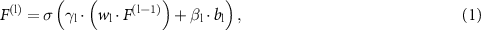
where 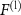 represents the output of the
represents the output of the 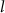 th hidden layer, with
th hidden layer, with 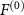 corresponding to the output of the input layer, and
corresponding to the output of the input layer, and 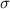 denotes the SIREN activation function (Sitzmann et al 2020).
denotes the SIREN activation function (Sitzmann et al 2020).
Figure 3 illustrates the case-specific adaptation stage, in which the cMeta-INR model is adapted to each patient-specific registration case by fine-tuning the parameters inherited from the meta-learned template 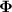 , using two steps of loss functions described in section 2.3. To reduce computational complexity, the spatial coordinates
, using two steps of loss functions described in section 2.3. To reduce computational complexity, the spatial coordinates 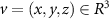 , representing voxel locations in Cartesian space, were downsampled and input to the INR, which output the corresponding voxel-wise DVF
, representing voxel locations in Cartesian space, were downsampled and input to the INR, which output the corresponding voxel-wise DVF 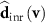 . The predicted DVF was subsequently upsampled to the original resolution and applied to the fully-sampled prior (source image
. The predicted DVF was subsequently upsampled to the original resolution and applied to the fully-sampled prior (source image 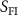 ) via a spatial transformation layer (Balakrishnan et al 2019) to obtain the deformed source image
) via a spatial transformation layer (Balakrishnan et al 2019) to obtain the deformed source image 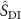 . This deformed image was then projected into the k-space domain using NUFFT, yielding the k-space data
. This deformed image was then projected into the k-space domain using NUFFT, yielding the k-space data 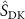 of the deformed source image that can be compared with the target k-space data
of the deformed source image that can be compared with the target k-space data 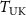 to guide INR optimization. Importantly, this test-time adaptation procedure was fully unsupervised and did not require ‘ground-truth’ DVFs, making it suitable for deployment in clinical settings with only undersampled k-space measurements.
to guide INR optimization. Importantly, this test-time adaptation procedure was fully unsupervised and did not require ‘ground-truth’ DVFs, making it suitable for deployment in clinical settings with only undersampled k-space measurements.
Figure 3. Case-specific adaptation, where the INR initialized via the learned INR template 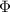 was further optimized for a new patient registration case using four loss functions: deformation discrepancy loss
was further optimized for a new patient registration case using four loss functions: deformation discrepancy loss 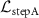 , k-space fidelity loss
, k-space fidelity loss 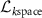 , embedding similarity loss
, embedding similarity loss 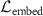 , and deformation smoothness loss
, and deformation smoothness loss 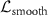 . The pre-trained KS-RegNet (frozen) predicts the DVFs used to calculate
. The pre-trained KS-RegNet (frozen) predicts the DVFs used to calculate 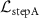 , the encoder of KS-RegNet is employed to extract feature embeddings for calculating the
, the encoder of KS-RegNet is employed to extract feature embeddings for calculating the 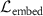 , and
, and 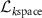 is computed between the undersampled target k-space data and the corresponding k-space data of the deformed source image.
is computed between the undersampled target k-space data and the corresponding k-space data of the deformed source image.
Download figure:
Standard image High-resolution image 2.3. Loss function design and training proceduresThe cMeta-INR framework comprised two stages: prior meta-learning for optimizing the INR template, and test-time adaptation for case-specific DVF inference. Both stages follow a two-step optimization scheme (step A and step B). For step A, a pre-trained, UNet-based KS-RegNet (Shao et al 2022) was used to predict the DVF 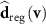 as the population-based reference for optimizing the INR via the mean absolute error loss function, denoted as cohort-informed deformation discrepancy loss:
as the population-based reference for optimizing the INR via the mean absolute error loss function, denoted as cohort-informed deformation discrepancy loss:
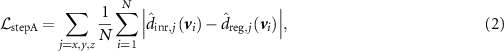
where 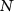 denotes the total voxel number of the DVF and
denotes the total voxel number of the DVF and 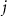 denotes the Cartesian direction.
denotes the Cartesian direction.
For step B, three loss functions were used to update the parameters of INR. We used the k-space fidelity loss to measure the similarity between the NUFFT-projected k-space data 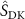 of the deformed source image (
of the deformed source image (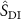 ) and the undersampled target k-space data
) and the undersampled target k-space data 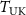 , and calculated the mean squared error between the two complex-valued k-space data as the k-space fidelity loss:
, and calculated the mean squared error between the two complex-valued k-space data as the k-space fidelity loss:
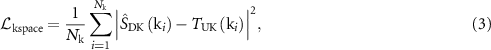
where 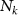 is the number of sampled points in k-space, and
is the number of sampled points in k-space, and 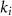 represents the ith sampling frequency.
represents the ith sampling frequency.
The k-space data typically concentrate in the low-frequency region due to MRI sampling patterns (Lustig et al 2008, Raja and Sinha 2014). To better capture high-frequency anatomical details, we introduced an embedding-space loss, which measured the semantic similarity between the latent space vectors of the deformed source image 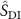 and the target image
and the target image 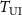 , termed embedding similarity loss. These embeddings were extracted using the encoder of the pre-trained KS-RegNet. The loss was formulated using the cosine similarity (Zhou et al 2024):
, termed embedding similarity loss. These embeddings were extracted using the encoder of the pre-trained KS-RegNet. The loss was formulated using the cosine similarity (Zhou et al 2024):
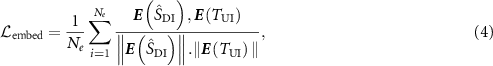
where 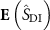 and
and 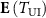 denote the latent embeddings of the deformed source and the target volumes, respectively,
denote the latent embeddings of the deformed source and the target volumes, respectively, 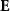 is the encoder, and
is the encoder, and 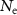 is the total number of embedding vectors. This loss encouraged semantic alignment in the feature space, helping preserve fine-grained structural information during registration.
is the total number of embedding vectors. This loss encouraged semantic alignment in the feature space, helping preserve fine-grained structural information during registration.
A third loss function was introduced to further regularize the smoothness of the DVFs. It calculated the mean deformation energy of the DVF via:
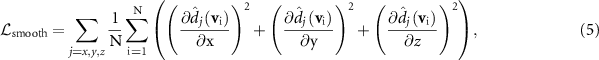
where 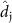 denotes a Cartesian component
denotes a Cartesian component 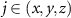 of
of 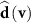 .
.
The total loss function in step B was a weighted sum of the three losses:
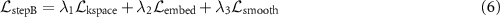
where 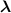 denote the weighting hyper-parameters. In this work,
denote the weighting hyper-parameters. In this work, 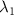 = 1.0,
= 1.0, 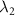 = 0.5, and
= 0.5, and 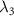 = 0.5 were empirically determined by trial-and-error experiments.
= 0.5 were empirically determined by trial-and-error experiments.
In the meta-learning process, the token-aware modulator, which generated modulation coefficients to condition the INR, was updated. Specifically, after several epochs of step A followed by step B to optimize the INR on a given case via stochastic gradient descent, the parameters of the modulation module were updated through backpropagation. Meanwhile, the meta-parameters of the INR template were updated by averaging the differences between the post-training and initial parameters across multiple subjects, similar to Reptile (Nichol et al 2018). During test-time adaptation, only a few epochs of steps A and B were used to fine-tune the INR for a new registration case. The complete training and test-time optimization strategy is summarized in algorithm 1.
Algorithm 1. cMeta-INR training and test-time adaptation.Input and Notation: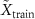 denotes the training dataset with
denotes the training dataset with 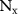 cases.
cases. 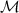 is the token-aware modulator with parameters
is the token-aware modulator with parameters 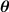 .
. 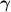 and
and 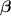 are the generated modulation parameters,
are the generated modulation parameters, 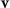 is the input to the INR,
is the input to the INR, 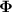 is the INR template, and
is the INR template, and  denotes its parameter update.
denotes its parameter update. 
Comments (0)