
Remember me






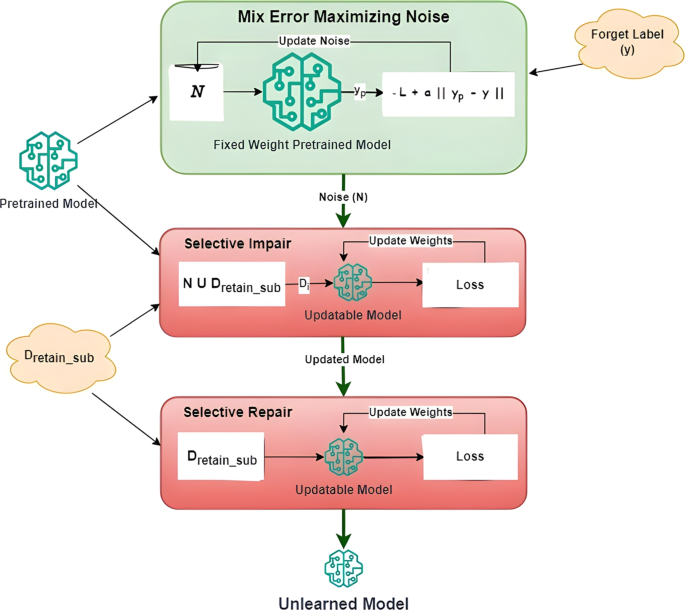


In this section, we present and compare the results of single and multiple-class unlearning using our proposed models with the previous techniques. Different models and datasets were used to assess the proposed methods’ abilities.
Comparison with UNSIR and Other Models on Various DatasetsWe perform two sets of experiments: single-class where \(\#y_f=1\), and multiple-class, where \(2 \ge \#y_f \ge m\). Recall that m is the number of classes in the dataset. In single-class unlearning, only one class is forgotten at any given time. In multiple-class unlearning, the model simultaneously forgets a subset of classes. For 10-class datasets, three cases: \(\#y_f = 2\), \(\#y_f = 3\), and \(\#y_f = 6\) were considered. For each case, five subsets of classes were created. The results shown in this section represent the mean of these five subsets. Three cases were also considered for the 100-class datasets: \(\#y_f = 20\), \(\#y_f = 40\), and \(\#y_f = 60\) and five subsets of classes were created for each case.
Recall that for impair, a noisy dataset (\(D_i\)) was created where \(D_i = D_} \cup \mathbb \). For repair, the subset of the retained dataset \(D_}\) was used. The batch size and the number of samples varied based on the dataset and model architecture. We learned the mix error-maximizing noise matrix with a single batch size for a single class. For multiple classes, we simultaneously learned the mix error-maximizing noise with the corresponding label. We did not train noise for multiple classes one by one.
Cifer10Table 1 compares the performance of our methods I) UNI(F)R, II) DNF with four previous approaches FineTuned [48], NegGrad [48], UNSIR [14] and ERM-KTP [49] using the Cifer10 dataset. A batch size of 250 was set for this dataset. The dataset \(D_\) was created by selecting 1000 random samples from \(D_\). We ran one epoch for impair and one epoch for repair, with learning rates set at 0.02 and 0.01, respectively, for both of our proposed methods. For the AllCNN model, we used learning rates of 0.009 and 0.001 for impair and repair, respectively. The \(Acc_r \uparrow \) represents the retain classes’ accuracy. The higher the better. The \(Acc_f \downarrow \) is the accuracy of the forget class and ideally must be zero.
For the rest of the datasets, we only compare our results with UNSIR [14] because it has the best results for both forget and retain among all of these previous models. We also compared the relearn time with UNSIR.
Table 1 Unlearning on CIFAR10: Original Model: Before Unlearning. FineTune: Fine-tuned on \(D_\) [48]. NegGrad: Fine-tuned on \(D_\) with negative gradients [48]. UNSIR: Single Pass Impair and Repair [14]. USI(F)R: Proposed Method I. DNF: Proposed Method II. \(R_t\): Relearn time in terms of epochs to regain original accuracy on \(D_\) (more epochs \(\propto \) better unlearning). \(\#Y_\): Unlearning class count VGGFace10Same batch size was used as Cifar10. \(D_\) consisted of at least 350 samples for each class. ResNet18 was used for this dataset, with a learning rate of 0.001 for impair and 0.0001 for repair. Both impair and repair were run for one epoch each. Table 2 highlights the results for this dataset.
Table 2 Comparison of UNSIR and USI(F)R methods for Unlearning Resnet18 model on VGGFace10 datasetTable 3 Comparison of UNSIR and USI(F)R methods for unlearning Resnet18 model on WildCat10 dataset WildCat10The batch size of 200 and 200 samples for each class were used (for \(D_\)). ResNet18 was used for this dataset, with a learning rate of 0.001 for impair and 0.0001 for repair. One epoch was run for both impair and repair. The results for Wildcat10 dataset are shown in Table 3.
Cifer100Only 100 samples were selected for each class, and the noise batch was limited to 5. In the case of ResNet18, we used a learning rate of 0.00065 for impair (damage) and 0.0001 for repair (healing). We ran one epoch for impair and 2 for repair. For MobileNetV2, the impair learning rate was set to 0.0007, and the repair learning rate was 0.0001. One epoch was run for impair and 2 epochs for repair. The noise batch was only 5, and 100 samples were used for each class. Results are shown in Table 4.
Table 4 Unlearning on CIFAR100 Dataset: Original Model: Model trained on complete dataset \(D_\) UNSIR: Unlearning with Single Pass Impair and Repair [14]. USI(F)R: Our Proposed Method I DNF: Our Proposed Method II \( \#Y_:\) Count of unlearning classes VGGFace100For this dataset, the batch size was 300, and noise batches were 5, with at least 250 samples for each class. ResNet18 was used for this dataset, with a learning rate of 0.0029 for impair and 0.0005 for repair. When #Y = 1, 20, one epoch was run for both impair and repair, and when #Y = 40, 60, one epoch was run for impair and two for repair. The results are shown in Table 5. The Vision Transformer was applied to this dataset, with the learning rate for impair set at 0.0004 and 0.0002. One epoch each was run for repair and impair.
Table 5 Unlearning on VGGFace100 Dataset: Original Model: Model trained on complete dataset \(D_\) UNSIR: Unlearning with Single Pass Impair and Repair [14]. USI(F)R: Our Proposed Method I DNF: Our Proposed Method II \( \#Y_:\) Count of unlearning classes MNISTDigit, MNISTFashion, CalTech10 and OnePieceAnime10Table 6 compares the proposed models with UNSIR on four different datasets in forget accuracy, retain accuracy and relearn time. We employed the ResNet18 model. For MNIST datasets, the learning rate was set to 0.02 for impair and 0.01 for repair. For the other two datasets, the learning rates for impair and repair were set at 0.001 and 0.0001, respectively. Each of these tasks was accomplished within a single epoch.
Table 6 Comparison of Original Model: UNSIR, with USI(F)R and DNF methods. Relearn Time: Relearn Time is the number of epochs taken by the model to regain accuracy close to the Original Model on \(D_\) dataset before unlearning shown for both methods. \( \#Y_:\) Count of unlearning classes DogBreed10, IndoorSceneRec10, GanoCatBreed10For these datasets, batch size of 250 was used with a fixed number of samples set at 100 for each class. The relearn sample size was set to 50. The results are are presented in Table 7.
In [49], the ERM-KTP approach is proposed. In this section, we also compare our proposed approaches with this study. We ran one epoch for impairment and one epoch for repair, with learning rates set at 0.02 and 0.01, respectively. The ERM-KTP model was trained from scratch with the default parameters of the model. We ran only one epoch for the ERM-KTP method results because our methods take only one epoch for the repairing phase. ERM-KTP also directly assigns zero weights to the forget class(es) at the classification layer making the forget accuracy irrelevant.
One important thing we have noted is that this approach starts retraining the model again. Obviously, retraining will achieve the good results presented in [49] and shown in Table 8, but this deviates from the real essence of unlearning. For our model, we ran only one epoch and still outperform the results of the study.
Table 7 Comparison of proposed methods USI(F)R and DNF with USIR using the vision transformer model (for DogBreed10) and MobileNetV2 (for ndoorSceneRec10, GanoCatBreed10)Table 8 Unlearning the Resnet20 model by the method ERM-KTP(Knowledge-level Machine Unlearning via Knowledge Transfer) with 82.65 on Cifar10: Original Model: Model trained on complete dataset \(D_\), accuracy of the model, ERM-KTP: Knowledge-level Machine Unlearning via Knowledge Transfer [49], USI(F)R: Our Proposed Method I, DNF: Our Proposed Method II, Time taken: Time taken to unlearn class(es) #Y: Count of unlearn label(s)Unlearning VisualizationThe GradCAM visualization technique proposed by [50] serves as a tool to generate visual explanations for decisions made by Convolutional Neural Networks (CNNs), highlighting the regions of the input image that are most influential in the model’s prediction. Figure 4 shows the regions of the images that the model learns to attend to for both retain and forget class. The images are taken from the VGGFace100 dataset using the Resnet18 model. The first column displays the original image, the second column showcases the GradCam visualization of the original model (pre-trained), and the last column illustrates the GradCam visualization of the Unlearned Model. Our methods demonstrate a sustained overall generalizability of the model on the retain dataset. In contrast, UNSIR claimed a loss in model generalizability using their method.
Our methods exhibit a consistent focus area both before and after unlearning in the Retain Class, indicating that they do not compromise the model’s attention to pertinent features. However, in the case of the Forget Class, the unlearned model deliberately loses focus on specific areas (e.g., face) for image classification. This observation suggests that our methods effectively erase information related to the forgetting class while preserving the model’s generalizability on the retained dataset.
Fig. 4 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Visualization of regions of interest identified by the Resnet18 model on VGGFace100 dataset using GradCAM
Time ComparisonThe total time taken to unlearn one or multiple classes in seconds serves as a key metric for assessing the model’s efficiency. For comparison, we exclusively consider UNSIR [14], as the deficiencies of previous models have already been extensively discussed within the context of UNSIR. When calculating total time, three phases are considered: Error Maximizing Noise, Impair, and Repair.
Table 9 compares the proposed model with UNSIR in terms of the time taken to unlearn using the VGGFace10 and WildCat10 datasets respectively. The results show that while UNSIR takes linearly increasing time, the time taken by our method decreases linearly. The comparison is also visualized in the form of graphs in Fig. 5 that show the total time taken in seconds to unlearn different numbers of labels (#Y = 1, 2, 3, 6). The DNF method was not considered since this method does not have the Error Maximizing step which automatically reduces the time. UNSIR trains a noise matrix for every class, so this approach takes too much time as compared to our model when the number of classes are increased (17.84 v. 1.9 seconds for 6 classes).
Table 9 Comparison of UNSIR and USI(F)R methods in terms of relearn time for unlearning Resnet18 model on VGGFace10 and WildCat10 datasets. The best times shown in bold. Time taken: Time taken to unlearn class(es) in seconds = Error Maximizing Noise + Impair + Repair #Y: Count of unlearn label(s)Fig. 5 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Comparison graphs between UNSIR [14] and our proposed USI(F)R method
The impair and repair take almost the same time for USI(F)R and [14] method. In the case of the VGGFace10 and Restnet18 model for one class unlearning our model took 2.3 seconds while UNSIR took 3.59 seconds. For the 2 classes unlearning our method decreased from 2.3 to 2.07 while the UNSIR increased from 3.59 to 4.79. For the 3 classes unlearning our method decreased from 2.07 to 2.03 while the UNSIR increased from 4.79 to 6.18 and so on.
This analysis shows that if we perform unlearning for many classes e.g., 20, 40, 60 [14] method will take too much time is the considerable issue in UNSIR, and our method’s applicability will increase here too. For the ResNet20 model, we compared our approaches with ERM-KTP [49].
We were able to forget the 1 class in less than 2 seconds, while ERM-KTP took almost 1.5 minutes. For the cases of 2, 3, and 6 classes, we are under 2 seconds, while ERM-KTP took over 1 minute. Our methods significantly outperform ERM-KTP in terms of computational efficiency.
DiscussionThis section provides a detailed discussion of the results presented in the previous subsection. Since UNSIR [14] has the best results for both forget and retain among all of these previous models, we limit our discussion to this base study.
Single Class UnlearningWe aimed to unlearn a single or specific class at a time. Our proposed methods demonstrated the capability to erase information related to a particular class while maintaining good accuracy for the retained dataset \(D_\). This was achieved through a one-shot impair and repair process, and in some instances, more than one repair might be necessary. The results are presented in Table 1 to Table 7.
Our proposed methods attained higher accuracy on the retained dataset (\(D_\)) and successfully eliminated information related to the forget dataset (\(D_\)) compared to previous methods [14, 48]. Not only did our methods achieve improved accuracy, but they also outperformed in relearn time comparisons. For the Resnet18 and Cifer10, our methods UNI(F)R and DNF sustain 74.97% and 74.45% accuracy on \(D_\) respectively, while the UNSIR [14] was able to get 71.06% Table 1. On the forget dataset (\(D_\)), both methods wipe out the information of a specific class and drop the accuracy from 80.01% to 0%. The number of epochs (Relearn Time) is also greater than the base methods, e.g., in the case of the Cifer10 dataset, AllCNN, and Resnet18 models > 110, > 100 respectively.
For the VGGFace100 and ResNet18 models (Tables 2 and 3), UNSIR failed to completely erase information associated with the target class, resulting in an information leakage of approximately 3%. In contrast, for the ResNet18 model trained on the MNISTDigit dataset, our method achieved accuracy comparable to that of the original model. For the MNISTFashion dataset, our method improved the average accuracy by approximately 2.5% over the original model. A more substantial gain was observed on the OnePieceAnime10 dataset, where our method achieved an average accuracy improvement of approximately 11.5%. For the CalTech10 dataset, our method incurred a modest reduction in performance, with an average accuracy drop of approximately 3% compared to the original model.
For the ViT model and DogBreed10 dataset, our methods dropped on average almost 3% the accuracy of the original model and for the VGGFace100 dataset the ViT dropped almost 5% on average. For the MobileNetV2 model and IndoorSceneRec10 dataset, our method I dropped almost 4% and method II dropped almost 2% of the accuracy of the original model. For the MobileNetV2 model and GanoCatBreed10 dataset, our method I dropped almost 7% and method II dropped almost 3% the accuracy of the original model.
Multiple Class UnlearningOur methods exhibit exceptional performance not only in single-class forgetting scenarios but also prove to be highly effective in multiple-class unlearning simultaneously. Specifically, considering the Cifer10 dataset and the Resnet18 model: in 2 class unlearning Table 1 our methods were able to achieve almost the same accuracy as the Original Model while the UNSIR was not almost 4.4% less than Original Model, in case of 4 class forget our both methods able to get accuracy more than Original Model while the UNSIR was again less than the Original Model, and in case of 7 class forget UNSIR was able to get only 3% more than the original model, on the other hand, our Method I able to get almost 9% and Method II almost 10% more than the Original Model Table 1.
For the AllCNN model and Cifer10 dataset: in case 2 classes forget our Method I was able to get almost 2% and Method II almost 4% more than the Original Model while the UNSIR was less than 4% the Original Model, in case 4 classes forget our both method on average get 8.5% more than the original model while the [14] drop almost 7%, and for the 7 classes forget our both method on average able to get 11% more than the Original Model while the UNSIR was able to get only 2%.
For the Cifer100 dataset Resnet18 model: in the case of \(\#y_f = 20\), forget our both methods were able to get almost the same accuracy while the UNSIR was less than almost 2% the Original Model, in the case of 40 classes forget our methods on greater than on average 2% and [14] able to get as same accuracy as the Original Model and in the 60 classes forget UNSIR almost drop 1% accuracy compared to the Original Model on the retain dataset and 0.47% on the forget dataset, while our methods were able to get almost the same accuracy as the Original Model and on forget, we were also able to get 0% on the forget dataset.
For MobileNetV2 and Cifer100 dataset: in the case of \(\#y_f = 20\), UNSIR able to perform equally well as compared to the original model whereas our methods recorded a drop of almost 2.5% accuracy. In the case of \(\#y_f = 40\) our method drops by 1% accuracy of the Original Model but gets 0% on the forget dataset. UNSIR has 1% more accuracy than the original model but was unable to wipe out the information of all classes. For the \(\#y_f = 26\) case our methods able to get almost same accuracy of the Original Model while the [14] not only drop 12% accuracy of the Original Model but also preserve the information of the classes Table 4.
For the VGGFace100 and resnet18: in the case of \(\#y_f = 20\) our Method I drop almost 7% and Method II almost 4% of the Original Model but also able to erase the information of forget classes while the UNSIR was unable to wipe out the information of the forget classes, in case of \(\#y_f = 40\) and \(\#y_f = 60\), UNSIR was unable to erase the information and gave an accuracy of 6.71%, 8.62% on the forget classes respectively. Our method, however, was able to wipe out the information of the forget classes and able to get 0% accuracy on those classes as shown in Table 5.
For ViT and VGGFace100: in the case of 20,40,60 classes unlearning our both model able to wipe out the information of the forgot classes while the UNSIR was unable to wipe out the information of the forgot classes 5, for 20 classes [14] giving 26% accuracy on forgot classes, 25.10% for 40 and 8.48% for the 60 classes case .On the other datasets, the performance of our methods in multiple classes of unlearning, e.g., #\(Y_f\) = 2, 3, 6 are shown in Tables 1-7. The multiple distributions of datasets, fine-tuned as well as scratch-trained models, and unlearning show the large-scale applicability of our methods.
Comments (0)