
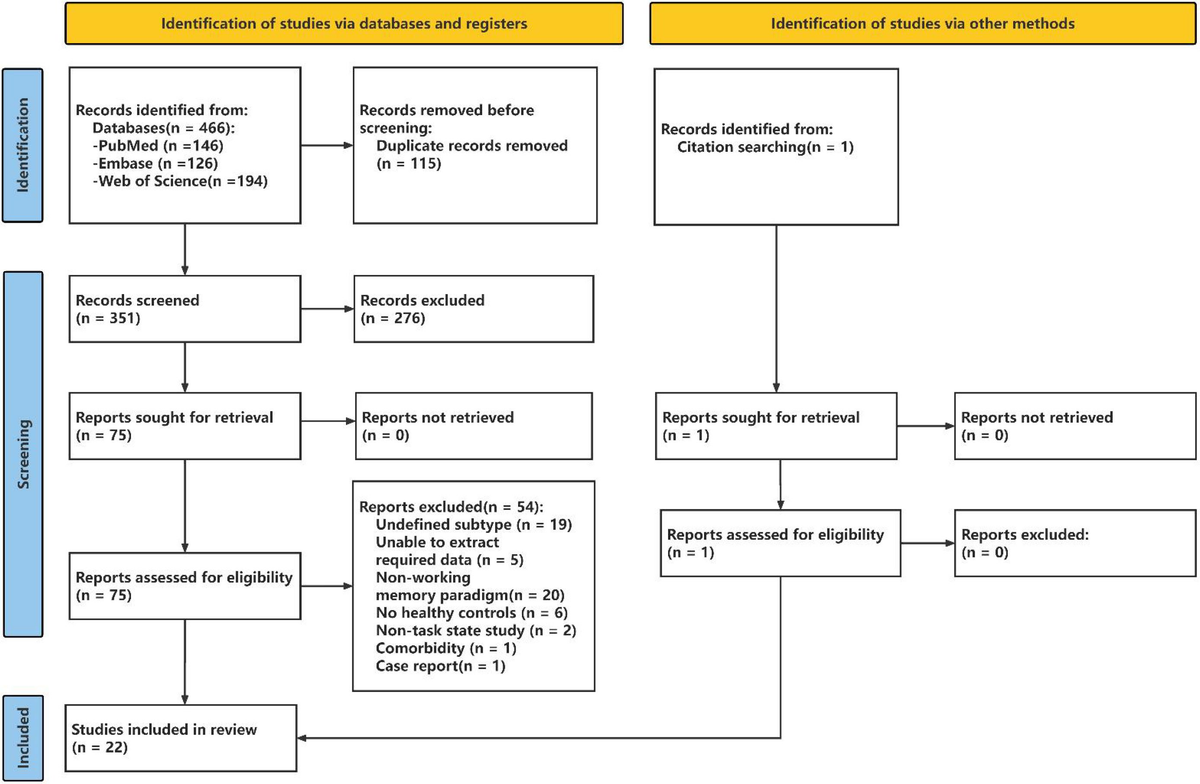
Remember me
Introduction:
Depression assessment remains largely dependent on symptom reports and clinician judgment, while objective tools for depressive-spectrum stratification and severity estimation remain limited. Existing digital and multimodal depression-detection studies often focus on binary case-control classification, handle missing modalities incompletely, provide limited calibration assessment, and rarely combine depressive-spectrum classification with continuous symptom-severity estimation. We therefore developed a quality-aware multimodal framework integrating eye tracking, facial behavior, and transcript-derived language for classification across normal control (NC), subthreshold depression (SD), and major depressive disorder (MDD), together with prediction of 17-item Hamilton Depression Rating Scale (HAMD-17) severity.
Methods:
A total of 186 participants completed a controlled task battery including interview, emotional reading, free viewing with verbal description, fixation, gaze orienting, smooth pursuit, prosaccade, and antisaccade tasks. Eye-tracking, facial-video, and transcript-derived language data were converted into modality-specific features. Baseline-3 combined modality-specific encoders, quality-aware gated fusion, and joint classification-regression learning under a nested repeated-resampling framework with explicit missing-modality handling. Baseline-3+ further incorporated Transformer-based cross-modal interaction and uncertainty-based dynamic task weighting. Performance was evaluated on held-out outer-loop test sets after temperature scaling. Interpretability analyses included gate profiling, selective prediction, SHAP, Integrated Gradients, and counterfactual analysis.
Results:
Baseline-3+ showed the most favorable classification and calibration profile, with accuracy, balanced accuracy, and F1-macro approaching 0.90 across both classification routes and lower expected calibration error than Baseline-3. For severity estimation, the improvement was route-dependent and mainly reduced the regression disadvantage observed under the hierarchical route. Misclassification was concentrated near the SD boundary. Interpretability analyses showed stable quality-aware modality reweighting, with facial features providing the dominant signal, complemented by eye tracking and smaller but meaningful language contributions.
Discussion:
This framework addresses key limitations of prior binary and incompletely calibrated depression-detection models by jointly supporting depressive-spectrum classification, severity estimation, missing-modality handling, calibrated prediction, and individual-level interpretation. Its most plausible role is to augment clinical assessment, particularly for boundary states such as SD.
1 IntroductionMajor depressive disorder (MDD) is a leading cause of disability worldwide and remains a major contributor to population disease burden (1). Despite its clinical importance, diagnosis still relies largely on symptom report and clinician judgment, and objective tools for screening, stratification, and longitudinal monitoring remain limited (2–6). Recent work in digital psychiatry and computational phenotyping has therefore focused on behavioral and physiological signals that may complement conventional assessment, although clinically transferable biomarkers for depression remain difficult to establish (7, 8). This challenge is especially relevant across the depressive spectrum. Subthreshold depression (SD) is more prevalent than syndromal MDD in many populations, is associated with functional impairment and elevated risk of progression, and is not adequately captured by symptom thresholds alone (9–12). Available evidence suggests that SD is not simply a milder form of MDD, but a heterogeneous intermediate state with variable symptom burden, psychosocial dysfunction, and transition risk. This heterogeneity also contributes to diagnostic ambiguity in data-driven models.
Behavioral markers used in depression-related modeling differ substantially in their biological and clinical meaning. Eye-tracking studies have linked depressive symptoms to altered visual attention, abnormal allocation to emotional stimuli, disturbed fixation, and impaired oculomotor control across fixation, saccade, and pursuit paradigms (13–19). These measures provide objective indices of attentional bias and cognitive control, although many studies remain focused on single-modality group discrimination or symptom association. Facial-behavior studies have used facial landmarks, head pose, and action-unit dynamics to quantify reduced expressivity, altered affective display, and impaired emotional flexibility (20–25). These features are clinically relevant because facial behavior forms part of routine mental-status assessment, but previous models have often emphasized binary depression detection or abnormalities in facial emotion processing rather than depressive-spectrum stratification. Language-based studies have examined transcript-derived text, acoustic speech, or audiovisual signals and have identified changes in fluency, self-reference, negation, affective wording, semantic structure, and speech characteristics (26–32). However, these studies differ in whether language is represented as text, audio, or combined speech-language information, and many focus on detecting depression status rather than jointly estimating clinical severity. Multimodal artificial intelligence has advanced automated depression assessment by integrating text, audio, facial behavior, eye tracking, and other behavioral signals (33–45). Existing models commonly use early fusion, late fusion, attention-based fusion, or deep representation learning to improve diagnostic discrimination, most often for binary depression detection or symptom-level prediction rather than simultaneous depressive-spectrum classification and severity estimation. These approaches have shown encouraging performance, but several limitations remain important for clinical translation. Many studies retain a binary case-control formulation, whereas fewer address intermediate depressive-spectrum states such as subthreshold depression. Missing or degraded modalities are often handled implicitly or by complete-case analysis, and probability calibration is rarely evaluated in detail. In addition, relatively few frameworks jointly model categorical depressive-spectrum status and continuous symptom severity while also providing individual-level interpretation. These gaps are particularly relevant when the target task extends beyond binary depression detection to spectrum-level stratification and symptom-severity estimation.
Against this background, we developed and evaluated a quality-aware multimodal framework that integrates eye tracking, facial behavior, and transcript-derived language acquired during a controlled behavioral task battery. The study was designed to move beyond conventional binary depression detection by modeling the depressive spectrum across normal control (NC), SD, and MDD, while also estimating continuous symptom severity using the 17-item Hamilton Depression Rating Scale (HAMD-17). Methodologically, the framework combines modality-specific representation learning, explicit modeling of modality availability and missingness, and quality-aware gated fusion, with an extended model incorporating Transformer-based cross-modal interaction and uncertainty-based dynamic task weighting. The evaluation further incorporated a nested repeated-resampling framework, post hoc probability calibration, component-ablation analyses, and individual-level interpretability. By linking spectrum-level classification, continuous severity estimation, missing-modality handling, calibrated prediction, and case-level explanation within a single framework, this study aimed to provide a more clinically interpretable approach for multimodal depressive-spectrum assessment, particularly for boundary states such as subthreshold depression. The framework was therefore evaluated as a calibrated and interpretable research prototype for depressive-spectrum stratification.
2 Materials and methods2.1 ParticipantsParticipants were recruited from Suzhou Municipal Hospital and Suyuan Community Health Service Station in Wuzhong District, Suzhou, China. The cohort comprised normal control (NC), subthreshold depression (SD), and major depressive disorder (MDD) groups. Diagnostic assessment was performed by licensed psychiatrists. MDD was diagnosed according to the International Classification of Diseases, 11th Revision (ICD-11), whereas SD and NC were defined using prespecified operational criteria supported by standardized rating scales. Clinical assessment and multimodal data acquisition were completed on the same day. The study was approved by the Ethics Committee of Suzhou Municipal Hospital (K-2025-278-K01). Written informed consent was obtained from all participants before enrollment. Detailed eligibility criteria and operational group definitions are provided in Appendix A.
2.2 Experimental proceduresAll assessments were conducted in a controlled laboratory setting. Participants were seated in a quiet room, instructed to maintain a natural posture, and asked to minimize large head movements. Eye movements were recorded using a Tobii Pro Nano eye tracker at 60 Hz, mounted below a 14.5-inch laptop display (1920 × 1080 pixels), with a viewing distance of approximately 60–70 cm. Facial behavior was recorded using an external high-definition camera at 1080p and 30 frames/s. Spoken responses were transcribed for downstream language-feature extraction and data-quality control; acoustic speech features were not modeled as an independent modality. Before formal testing, a nine-point eye-tracking calibration was completed and repeated if necessary. Standardized instructions were provided before each task, and brief practice trials were given when required. A 30-s rest interval was arranged between adjacent tasks. The task battery included a sociodemographic questionnaire, a semi-structured interview, emotional text reading, emotional free viewing with verbal description, fixation stability, lateral gaze orienting, smooth pursuit, prosaccade, and antisaccade paradigms. Horizontal and sinusoidal pursuit conditions were both included. The interview and free-viewing tasks yielded transcript-derived language, whereas emotional text reading contributed eye-tracking and facial-behavior responses but was not used as an independent source for language modeling. Detailed task procedures are provided in Appendix B.
2.3 Multimodal preprocessing and feature engineeringRaw eye-tracking signals were processed using the velocity-threshold identification algorithm to classify fixations, saccades, and blinks. Samples outside the display region were discarded, and trials with a tracking ratio below 50% were excluded. A total of 723 participant-level eye-tracking features were extracted, covering fixation, visit, gaze transition, saccadic control, and higher-order cognitive and affective indices. Facial videos were analyzed frame by frame using OpenFace 2.0 to derive facial landmarks, head-pose measures, and facial action unit features. Frames with confidence below 0.7 or failed tracking were removed, and segments with a valid-frame ratio below 50% were excluded. Summary statistics and composite indices were then generated to quantify facial movement, affective expression, and task-related emotional regulation. The language modality was derived from offline transcription of spoken responses using Whisper large-v3 deployed through an OpenVINO-based workflow. Text preprocessing included normalization, sentence segmentation, identification of short segments, and conservative token filtering. Features were computed at the segment level and aggregated at the participant level within each task and emotional condition. The final language feature space included completeness and quality measures, structural and fluency indices, clinically relevant linguistic markers, and affective lexical features.
Across modalities, preprocessing, feature filtering, standardization, and feature selection were performed strictly within the training data of each resampling split to prevent information leakage. In the present study, modalities were defined by distinct data representations and processing pipelines, namely oculomotor behavior, facial behavioral dynamics, and transcript-derived linguistic features, rather than by whether they originated from separate acquisition sessions. Further details are provided in Appendix C. The outer-test data were transformed using parameters and feature sets learned exclusively from the corresponding training partition. To improve reproducibility and provide an auditable basis for subsequent modeling, the three modality-specific participant-level feature tables were first harmonized into a single raw multimodal master table before resampling-based model development. Eye-tracking, facial-behavior, and transcript-derived language features were prefixed by modality and aligned using a unique participant identifier. Diagnostic group labels and HAMD-17 scores were cross-checked across the three source tables before consensus labels were assigned. No imputation, winsorization, standardization, feature filtering, feature selection, calibration, or model training was performed during master-table construction. These procedures were deliberately deferred to the training data within each resampling split to prevent information leakage. The master table also retained modality-availability indicators and raw modality-specific missingness ratios for subsequent missing-modality modeling. Additional details on data alignment, master-table construction, missing-modality handling, and resampling-based model development are provided in Appendix D.
2.4 Multimodal modelingTabular features from the eye-tracking, facial, and language modalities were aligned by unique participant identifier. The classification target was depressive-status group membership (NC, SD, or MDD), and the regression target was HAMD-17. To accommodate incomplete multimodal acquisition, modality-level meta-features were constructed, including availability indicators and modality-specific missing ratios. Entire feature blocks for unavailable modalities were set to zero after fold-specific preprocessing. Model development followed a nested repeated-resampling framework. The three diagnostic groups were balanced by design, with 62 participants in each group. In the outer loop, data were repeatedly divided into training and held-out test sets using stratified 85:15 random partitioning over five repeats. Within each outer-training partition, five-fold stratified inner cross-validation was used for hyperparameter selection and early stopping. This design preserved class distribution across training and test partitions. In addition to ACC, we reported BACC, F1-macro, and class-level recall to avoid overinterpreting overall accuracy. Within each inner-loop training fold, modality-specific preprocessing included missingness filtering, median imputation, winsorization, low-variance filtering, redundancy reduction based on Spearman correlation, and z-score normalization. Supervised feature selection was then performed using repeated subsampling stability selection with elastic-net multinomial logistic regression. Because the downstream framework jointly modeled depressive-spectrum classification and HAMD-17 regression, feature selection was anchored to the classification structure to retain stable disease-relevant signals, while continuous severity estimation was learned jointly within the subsequent multimodal model.
The primary multimodal model, Baseline-3, combined modality-specific multilayer perceptron encoders with quality-aware gated fusion and joint classification-regression learning. For each modality m, where , the preprocessed input vector xm was mapped to a latent modality representation by a modality-specific encoder, . Quality metadata qm, including modality-availability indicators and modality-specific missingness ratios, were used together with modality embeddings to generate normalized gating weights αm. The Baseline-3 fused representation was then defined as , and was passed to separate classification and HAMD-17 regression heads. Baseline-3+ extended this architecture by treating modality embeddings as modality tokens and processing them through a lightweight Transformer encoder to obtain an interaction-aware shared representation. The multitask objective jointly optimized depressive-spectrum classification and HAMD-17 regression. In Baseline-3+, uncertainty-based dynamic task weighting assigned learnable task-uncertainty parameters to the classification and regression losses, allowing the relative contribution of each task to be adjusted during optimization. PCGrad was not included in the full Baseline-3+ model and was evaluated separately as a sensitivity arm under fixed task weighting. The full mathematical formulations of modality-specific encoding, quality-aware gated fusion, Route A and Route B probability reconstruction, Transformer-based interaction, dynamic task weighting, temperature scaling, expected calibration error, and ablation settings are provided in Supplementary Appendix E.
Two classification routes were implemented. Route A directly predicted NC, SD, and MDD. Route B used a hierarchical two-stage design that first separated NC from the depressive spectrum and then distinguished SD from MDD within spectrum-positive samples. Training incorporated modality dropout, AdamW optimization, and gradient clipping. Modality dropout was applied only during training; during each training iteration, available modality embeddings could be randomly masked according to the hyperparameter selected within the inner cross-validation loop. Validation and outer-test evaluation used the true observed modality-availability pattern without artificial dropout. Temperature-scaling parameters were fitted on validation predictions derived exclusively from the training portion of each outer split and were then applied unchanged to the corresponding outer-test predictions. The overall architecture of the proposed quality-aware multimodal framework, including fold-wise preprocessing, modality-specific encoding, quality-aware gated fusion, Baseline-3+ extensions, multitask outputs, calibration, and interpretability analysis, is summarized in Figure 1.

Overview of the quality-aware multimodal framework for depressive-spectrum classification and severity estimation. The image summarizes the overall study workflow. Multimodal inputs included eye-tracking, facial-behavior, and transcript-derived language features together with quality metadata describing modality availability and missingness. After resampling-specific preprocessing and feature selection, modality-specific multilayer perceptron encoders generated modality embeddings. In Baseline-3, these embeddings were integrated by quality-aware gated fusion, whereas Baseline-3+ further incorporated Transformer-based cross-modal interaction and uncertainty-based dynamic task weighting; PCGrad was evaluated separately as a sensitivity analysis under fixed task weighting. The shared representation supported multitask outputs for depressive-spectrum classification and HAMD-17 severity estimation, followed by calibration and interpretability analyses. ACC, accuracy; AUC-OVR, one-vs-rest macro-averaged area under the receiver operating characteristic curve; BACC, balanced accuracy; ECE, expected calibration error; HAMD-17, 17-item Hamilton Depression Rating Scale; MDD, major depressive disorder; MLP, multilayer perceptron; NC, normal control; PCGrad, Projected Conflicting Gradient; SD, subthreshold depression.
2.5 Evaluation and interpretabilityClassification performance was assessed using accuracy (ACC), balanced accuracy (BACC), one-vs-rest macro-averaged area under the receiver operating characteristic curve (AUC-OVR), macro-averaged F1 score (F1-macro), and log loss. Regression performance was assessed using mean absolute error (MAE), root mean squared error (RMSE), and coefficient of determination (R2). Metrics were calculated on the outer-loop test sets and summarized across repeated splits as mean ± standard deviation. Interpretability was evaluated at both the modality and individual levels. Gating-weight distributions were examined overall, by diagnostic group, and by missingness burden. Individual-level explanations were derived using Integrated Gradients (IG) and counterfactual analysis under modality-availability constraints. To characterize factors associated with classification failure and regression error, surrogate models based on uncertainty, calibration, missingness, gating, and attention features were additionally analyzed using SHapley Additive exPlanations (SHAP). Full details of the fusion models, calibration, evaluation metrics, and interpretability analyses are provided in Supplementary Appendix E. Case-level interpretability analyses were conducted on the held-out outer-test set of one representative Baseline-3+ Route B outer repeat selected for illustrative analysis. This test set comprised 28 participants. To further address calibration and statistical robustness, we re-analyzed the original outer-test prediction files after temperature scaling. Expected calibration error was calculated using the maximum calibrated class probability and empirical correctness across 10 equal-width confidence bins. Metric values were summarized across the five outer-loop test repeats as mean with 95% confidence intervals. Ninety-five percent confidence intervals were calculated across the five outer repeats using the t distribution and were interpreted as descriptive resampling uncertainty summaries rather than as population-level inferential intervals. Paired comparisons between Baseline-3 and Baseline-3+ were performed across matched outer repeats using sign-flip permutation tests. Because only five outer repeats were available, these tests were interpreted as exploratory repeat-consistency analyses rather than confirmatory hypothesis tests.
Component-level ablation analyses were conducted to clarify the contribution of the main Baseline-3+ extensions. The full Baseline-3 and full Baseline-3+ models were retained as reference settings. Additional ablation settings selectively removed uncertainty-based dynamic task weighting or Transformer-based cross-modal interaction, and a PCGrad sensitivity arm was evaluated under fixed task weighting. Ablation results were summarized using the same outer-test discrimination, calibration, and HAMD-17 regression metrics as the full models. To provide a representative conventional reference aligned with common early-fusion tabular modeling strategies, we additionally evaluated regularized linear benchmark models within the same nested repeated-resampling framework. Elastic-net logistic regression was used for depressive-spectrum classification, and Ridge regression was used for HAMD-17 severity estimation. These models were selected a priori because they are interpretable and appropriate for high-dimensional small-sample tabular data. The benchmark analyses were performed using stability-selected single-modality features and early-fusion features across all modalities. These conventional models were interpreted as reference analyses of the extracted feature space rather than as replacements for the proposed quality-aware multitask framework, because they do not model modality quality, joint classification-regression learning, calibrated uncertainty, or individual-level multimodal explanation.
3 Results3.1 Participant characteristicsA total of 186 participants were included, comprising 62 NC, 62 individuals with SD, and 62 patients with MDD. The reproducible multimodal master table contained 723 eye-tracking features, 2021 facial-behavior features, and 1029 transcript-derived language features. Cross-table verification identified no inconsistencies in diagnosis labels or HAMD-17 scores. Complete three-modality data were available for 168 participants, whereas 18 participants had at least one unavailable modality, supporting the use of modality-availability encoding and missingness-aware fusion. The master-table construction and modality-availability patterns are summarized in Supplementary Table 1 and S2. Baseline demographic and clinical characteristics are presented in Table 1. The three groups were broadly comparable in age, sex, education, marital status, offspring status, living arrangement, and eye-tracking acquisition quality. Occupational distribution and body mass index showed significant omnibus differences, although no adjusted pairwise comparison remained significant after multiple-testing correction. Several lifestyle and psychosocial variables differed across groups. Satisfaction with current income, sleep status, dietary pattern, physical exercise, cognitive activity, social participation, and psychological disclosure all showed significant between-group differences, generally shifting from more favorable profiles in NC toward less favorable profiles in SD and MDD. By contrast, smoking history, alcohol use, and household-work involvement did not differ significantly. Clinical symptom burden also differed markedly. Scores on the Center for Epidemiologic Studies Depression Scale, the 17-item Hamilton Depression Rating Scale (HAMD-17), the 7-item Generalized Anxiety Disorder scale, and the 14-item Hamilton Anxiety Rating Scale increased stepwise from NC to SD to MDD, with significant pairwise differences throughout. Anxiety-category distribution showed the same gradient. Together, these findings were consistent with the expected clinical ordering of the three groups and indicated increasing depressive and anxiety burden across the spectrum.
CharacteristicNC (n=62)SD (n=62)MDD (n=62)χ²/HP valueAge, y54.50 (31.25, 65.00)44.00 (30.00, 59.75)40.50 (29.25, 56.75)5.8260.054Sex, n (%)3.1500.207 Female39 (62.90%)44 (70.97%)48 (77.42%) Male23 (37.10%)18 (29.03%)14 (22.58%)Education level, n (%)7.1530.520 Compulsory education17 (27.42%)12 (19.35%)12 (19.35%) Basic education8 (12.90%)14 (22.58%)16 (25.81%) Vocational education1 (1.61%)4 (6.45%)3 (4.84%) Professional education31 (50.00%)26 (41.94%)28 (45.16%) Postgraduate education5 (8.06%)6 (9.68%)3 (4.84%)Employment type, n (%)14.6850.023 d Mainly manual labor9 (14.52%)13 (20.97%)11 (17.74%) Mixed manual and mental labor15 (24.19%)18 (29.03%)17 (27.42%) Mainly mental labor35 (56.45%)30 (48.39%)23 (37.10%) Unemployed3 (4.84%)1 (1.61%)11 (17.74%)Satisfaction with current income28.032< 0.001 a,b,c Dissatisfied6 (9.68%)8 (12.90%)22 (35.48%) Neutral27 (43.55%)41 (66.13%)30 (48.39%) Satisfied29 (46.77%)13 (20.97%)10 (16.13%)Marital status, n (%)9.5820.143 Married45 (72.58%)42 (67.74%)38 (61.29%) Unmarried13 (20.97%)19 (30.65%)18 (29.03%) Divorced0 (0%)0 (0%)3 (4.84%) Widowed4 (6.45%)1 (1.61%)3 (4.84%)Children, n (%)3.7080.157 With children47 (75.81%)41 (66.13%)37 (59.68%) Without children15 (24.19%)21 (33.87%)25 (40.32%)Living arrangement, n (%)1.4470.485 Living alone11 (17.74%)15 (24.19%)10 (16.13%) Not living alone51 (82.26%)47 (75.81%)52 (83.87%) Height, m1.63 (1.58, 1.70)1.62 (1.60, 1.68)1.60 (1.60, 1.66)0.4480.799 Weight, kg58.15 (53.62, 67.00)55.00 (52.00, 64.75)54.00 (50.00, 64.50)5.5270.063 BMI, kg/m²22.75 (20.58, 24.23)21.61 (19.84, 22.94)20.89 (19.56, 23.07)6.6050.037 dSleep status, n (%)75.912< 0.001 a,b,c Normal39 (62.90%)14 (22.58%)4 (6.45%) Poor sleep quality21 (33.87%)27 (43.55%)15 (24.19%) Insomnia2 (3.23%)21 (33.87%)43 (69.35%)Dietary pattern, n (%)26.763< 0.001 b,c Mainly vegetarian4 (6.45%)2 (3.23%)20 (32.26%) Balanced52 (83.87%)56 (90.32%)39 (62.90%) Mainly meat-based6 (9.68%)4 (6.45%)3 (4.84%)Smoking status, n (%)3.0150.807 Never53 (85.48%)53 (85.48%)50 (80.65%) Occasional2 (3.23%)3 (4.84%)5 (8.06%) Regular3 (4.84%)4 (6.45%)5 (8.06%) Quit4 (6.45%)2 (3.23%)2 (3.23%)Alcohol use, n (%)7.0890.313 Never46 (74.19%)49 (79.03%)38 (61.29%) Occasional12 (19.35%)9 (14.52%)18 (29.03%) Regular2 (3.23%)2 (3.23%)5 (8.06%) Quit2 (3.23%)2 (3.23%)1 (1.61%)Physical exercise, n (%)37.366< 0.001 a,b,c Never13 (20.97%)29 (46.77%)45 (72.58%) Occasional22 (35.48%)21 (33.87%)11 (17.74%) Regular27 (43.55%)12 (19.35%)6 (9.68%)Cognitive activities, n (%)19.350< 0.001 c Never23 (37.10%)37 (59.68%)47 (75.81%) Occasional25 (40.32%)15 (24.19%)9 (14.52%) Regular14 (22.58%)10 (16.13%)6 (9.68%)Housework, n (%)8.2980.081 None2 (3.23%)9 (14.52%)12 (19.35%) Partial36 (58.06%)35 (56.45%)31 (50.00%) All24 (38.71%)18 (29.03%)19 (30.65%)Social activities, n (%)66.599< 0.001 a,b,c None5 (8.06%)33 (53.23%)49 (79.03%) 1–3/month41 (66.13%)21 (33.87%)11 (17.74%) 4–6/month9 (14.52%)3 (4.84%)0 (0%)
Comments (0)