Sallam M. ChatGPT utility in healthcare education, research, and practice: systematic review on the promising perspectives and valid concerns. Healthcare. 2023. https://doi.org/10.3390/healthcare11060887.
Article
PubMed
PubMed Central
Google Scholar
Singhal K, et al. Large language models encode clinical knowledge. Nature. 2023;620:172–80.
Article
CAS
PubMed
PubMed Central
Google Scholar
Thirunavukarasu AJ, Ting DSJ, Elangovan K, Gutierrez L, Tan TF, Ting DSW. Large language models in medicine. Nat Med. 2023;29:1930–40.
Article
CAS
PubMed
Google Scholar
Abd-Alrazaq A, et al. Large language models in medical education: opportunities, challenges, and future directions. JMIR Med Educ. 2023;9:e48291.
Article
PubMed
PubMed Central
Google Scholar
Evans J, D’Souza J, Auer S. Large language models as evaluators for scientific synthesis. arXiv preprint http://arxiv.org/abs/240702977. 2024.
Luo Z, Yang Z, Xu Z, Yang W, Du X. Llm4sr: A survey on large language models for scientific research. arXiv preprint http://arxiv.org/abs/250104306. 2025.
Hamad F, Shehata A. The potential of GPTs for enhanced information access and user services at academic libraries. IFLA J. 2024. https://doi.org/10.1177/03400352241298958.
Article
Google Scholar
Gallifant J, et al. Peer review of GPT-4 technical report and systems card. PLoS Digit Health. 2024;3:e0000417.
Article
PubMed
PubMed Central
Google Scholar
Ko JS, Heo H, Suh CH, Yi J, Shim WH. Adherence of studies on large language models for medical applications published in leading medical journals according to the MI-CLEAR-LLM checklist. Korean J Radiol. 2025. https://doi.org/10.3348/kjr.2024.1161.
Article
PubMed
PubMed Central
Google Scholar
Huo B, et al. Large language models for chatbot health advice studies: a systematic review. JAMA Netw Open. 2025;8:e2457879-e.
Article
Google Scholar
Park SH, Suh CH, Lee JH, Kahn JCE, Moy L. Minimum reporting items for clear evaluation of accuracy reports of large language models in healthcare (MI-CLEAR-LLM). Korean J Radiol. 2024;25:865.
Article
PubMed
PubMed Central
Google Scholar
Gallifant J, et al. The TRIPOD-LLM reporting guideline for studies using large language models. Nat Med. 2025. https://doi.org/10.1038/s41591-024-03425-5.
Article
PubMed
PubMed Central
Google Scholar
Moy L. Guidelines for use of large language models by authors, reviewers, and editors: considerations for imaging journals. Radiol Soc N Am. 2023;309:e239024.
Google Scholar
Collaborative C. Protocol for the development of the Chatbot assessment reporting tool (CHART) for clinical advice. BMJ Open. 2024;14:e081155.
Article
Google Scholar
Cacciamani GE, et al. Development of the ChatGPT, generative artificial intelligence and natural large language models for accountable reporting and use (CANGARU) guidelines. arXiv preprint http://arxiv.org/abs/230708974. 2023.
Park SH, Suh CH. Reporting guidelines for artificial intelligence studies in healthcare (for both conventional and large language models): what’s new in 2024. Korean J Radiol. 2024;25:687.
Article
PubMed
PubMed Central
Google Scholar
Krag CH, et al. Large language models for abstract screening in systematic-and scoping reviews: a diagnostic test accuracy study. medRxiv. 2024;2024.10. 01.24314702.
Zhuang Z, Chen J, Xu H, Jiang Y, Lin J. Large language models for automated scholarly paper review: a survey. arXiv preprint http://arxiv.org/abs/250110326. 2025.
Chu Z, Ai Q, Tu Y, Li H, Liu Y. Pre: A peer review based large language model evaluator. arXiv preprint http://arxiv.org/abs/240115641. 2024.
Xie Y, et al. A preliminary study of o1 in medicine: Are we closer to an ai doctor? arXiv preprint http://arxiv.org/abs/240915277. 2024.
Lin Z, et al. Performance analysis of large language models Chatgpt-4o, OpenAI O1, and OpenAI O3 mini in clinical treatment of pneumonia: a comparative study. Clin Exp Med. 2025;25:213.
Article
PubMed
PubMed Central
Google Scholar
Xu S, et al. Towards next-generation medical agent: How o1 is reshaping decision-making in medical scenarios. arXiv preprint http://arxiv.org/abs/241114461. 2024.
Choi A, Kim HG, Choi MH, Ramasamy SK, Kim Y, Jung SE. Performance of GPT-4 turbo and GPT-4o in Korean Society of Radiology In-Training Examinations. Korean J Radiol. 2025;26:524.
Article
PubMed
PubMed Central
Google Scholar
Tomita K, Nishida T, Kitaguchi Y, Kitazawa K, Miyake M. Image recognition performance of GPT-4V (ision) and GPT-4o in ophthalmology: use of images in clinical questions. Clin Ophthalmol. 2025. https://doi.org/10.2147/OPTH.S494480.
Article
PubMed
PubMed Central
Google Scholar
Temsah M-H, Jamal A, Alhasan K, Temsah AA, Malki KH. OpenAI o1-preview vs. ChatGPT in healthcare: a new frontier in medical AI reasoning. Cureus. 2024;16:e70640.
PubMed
PubMed Central
Google Scholar
Kim H, Kim B, Choi MH, Choi J-I, Oh SN, Rha SE. Conversion of mixed-language free-text CT reports of pancreatic cancer to National Comprehensive Cancer Network structured reporting templates by using GPT-4. Korean J Radiol. 2025. https://doi.org/10.3348/kjr.2024.1228.
Article
PubMed
PubMed Central
Google Scholar
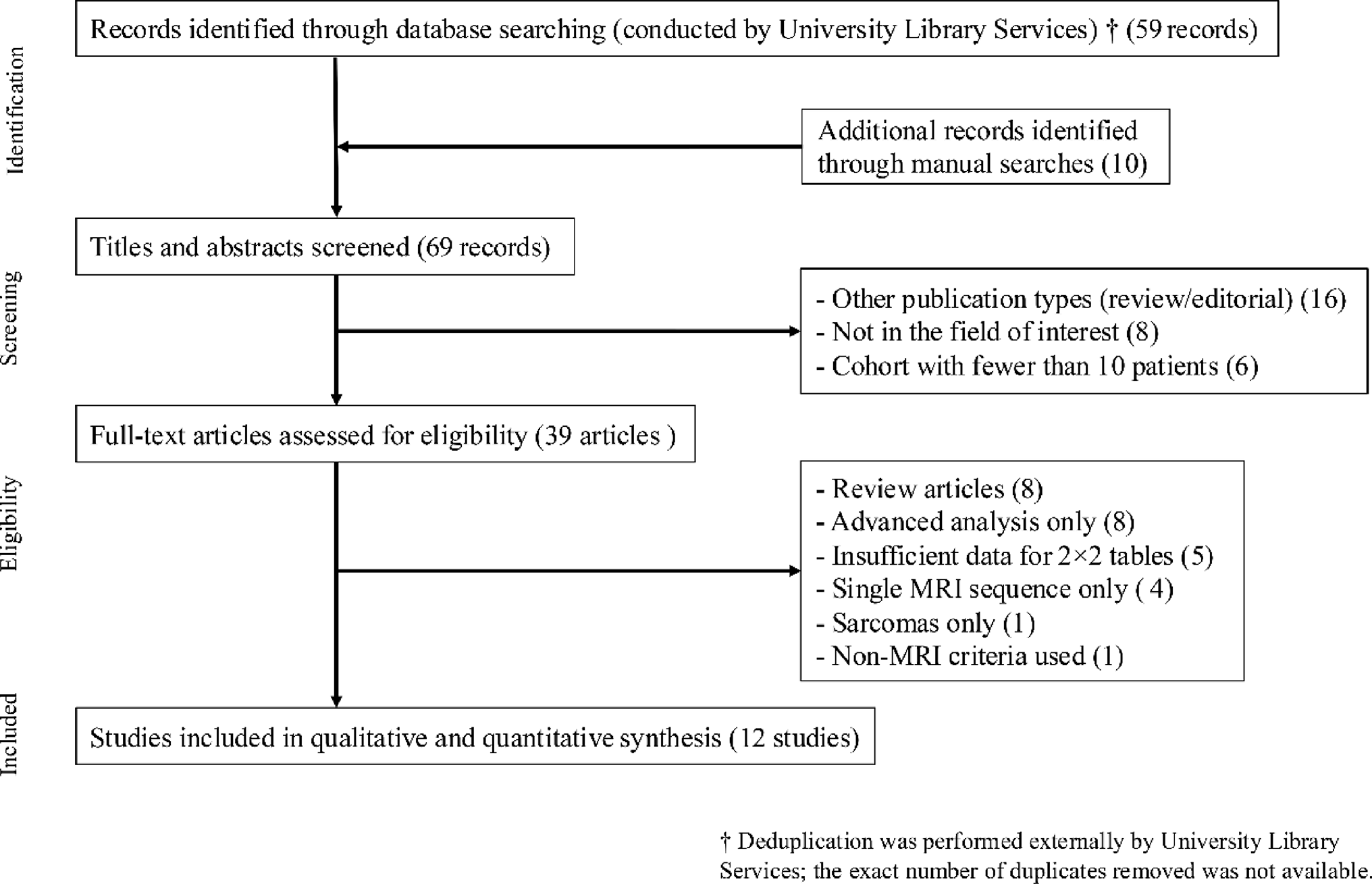
Page MJ, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372:n71.
Article
PubMed
PubMed Central
Google Scholar
Park HY, Suh CH, Woo S, Kim PH, Kim KW. Quality reporting of systematic review and meta-analysis according to PRISMA 2020 guidelines: results from recently published papers in the Korean Journal of Radiology. Korean J Radiol. 2022;23:355–69.
Article
PubMed
PubMed Central
Google Scholar
Suh CH, Yi J, Shim WH, Heo H. Insufficient transparency in stochasticity reporting in large language model studies for medical applications in leading medical journals. Korean J Radiol. 2024;25:1029.
Article
PubMed
PubMed Central
Google Scholar
Sawamura S, Kohiyama K, Takenaka T, Sera T, Inoue T, Nagai T. An evaluation of the performance of OpenAI-o1 and GPT-4o in the Japanese National Examination for Physical Therapists. Cureus. 2025. https://doi.org/10.7759/cureus.76989.
Article
PubMed
PubMed Central
Google Scholar
Goto H, Shiraishi Y, Okada S. Performance evaluation of GPT-4o and o1-preview using the certification examination for the Japanese ‘operations chief of radiography with X-rays.’ Cureus. 2024;16:e74262.
PubMed
PubMed Central
Google Scholar
Renze M. The effect of sampling temperature on problem solving in large language models. In: Findings of the association for computational linguistics: EMNLP 2024; 2024, 7346-56.
Landis JR, Koch GG. The measurement of observer agreement for categorical data. Biometrics. 1977. https://doi.org/10.2307/2529310.
Article
PubMed
Google Scholar
Liu R, Geng J, Wu AJ, Sucholutsky I, Lombrozo T, Griffiths TL. Mind your step (by step): Chain-of-thought can reduce performance on tasks where thinking makes humans worse. arXiv preprint http://arxiv.org/abs/241021333. 2024.
Chen X, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint http://arxiv.org/abs/241221187. 2024.
Kamesh R. Think beyond size: dynamic prompting for more effective reasoning. arXiv preprint http://arxiv.org/abs/241008130. 2024.
Chou S-H, Chandhok S, Little J, Sigal L. MM-R3: On (in-) consistency of vision-language models (VLMs). In: Findings of the association for computational linguistics: ACL 2025; 2025, 4762-88.
Pfitzmann B, Auer C, Dolfi M, Nassar A, Staar P. Doclaynet: A large humanannotated dataset for document-layout analysis. 2022. http://arxiv.org/abs/2206.1062:17.
Biswas A, Talukdar W. Robustness of structured data extraction from in-plane rotated documents using multi-modal large language models (LLM). J Artif Intell Res. 2024.
Polak MP, Morgan D. Extracting accurate materials data from research papers with conversational language models and prompt engineering. Nat Commun. 2024;15:1569.
Article
CAS
PubMed
PubMed Central
Google Scholar
Dunn A, et al. Structured information extraction from complex scientific text with fine-tuned large language models. arXiv preprint http://arxiv.org/abs/221205238. 2022.
Polak MP, et al. Flexible, model-agnostic method for materials data extraction from text using general purpose language models. Digit Discov. 2024;3:1221–35.
Article
Google Scholar
Mirzadeh I, Alizadeh K, Shahrokhi H, Tuzel O, Bengio S, Farajtabar M. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint http://arxiv.org/abs/241005229. 2024.
Irugalbandara C, et al. Scaling down to scale up: a cost-benefit analysis of replacing OpenAI’s LLM with open source SLMs in production. In: 2024 IEEE international symposium on performance analysis of systems and software (ISPASS): IEEE; 2024, pp. 280–291.
Wei J, et al. Chain-of-thought prompting elicits reasoning in large language models. Adv Neural Inf Process Syst. 2022;35:24824–37.
Google Scholar
Ferrag MA, Tihanyi N, Debbah M. Reasoning beyond limits: advances and open problems for LLMs. ICT Express. 2025. https://doi.org/10.1016/j.icte.2025.09.003.
Article
Google Scholar





Comments (0)