
Remember me
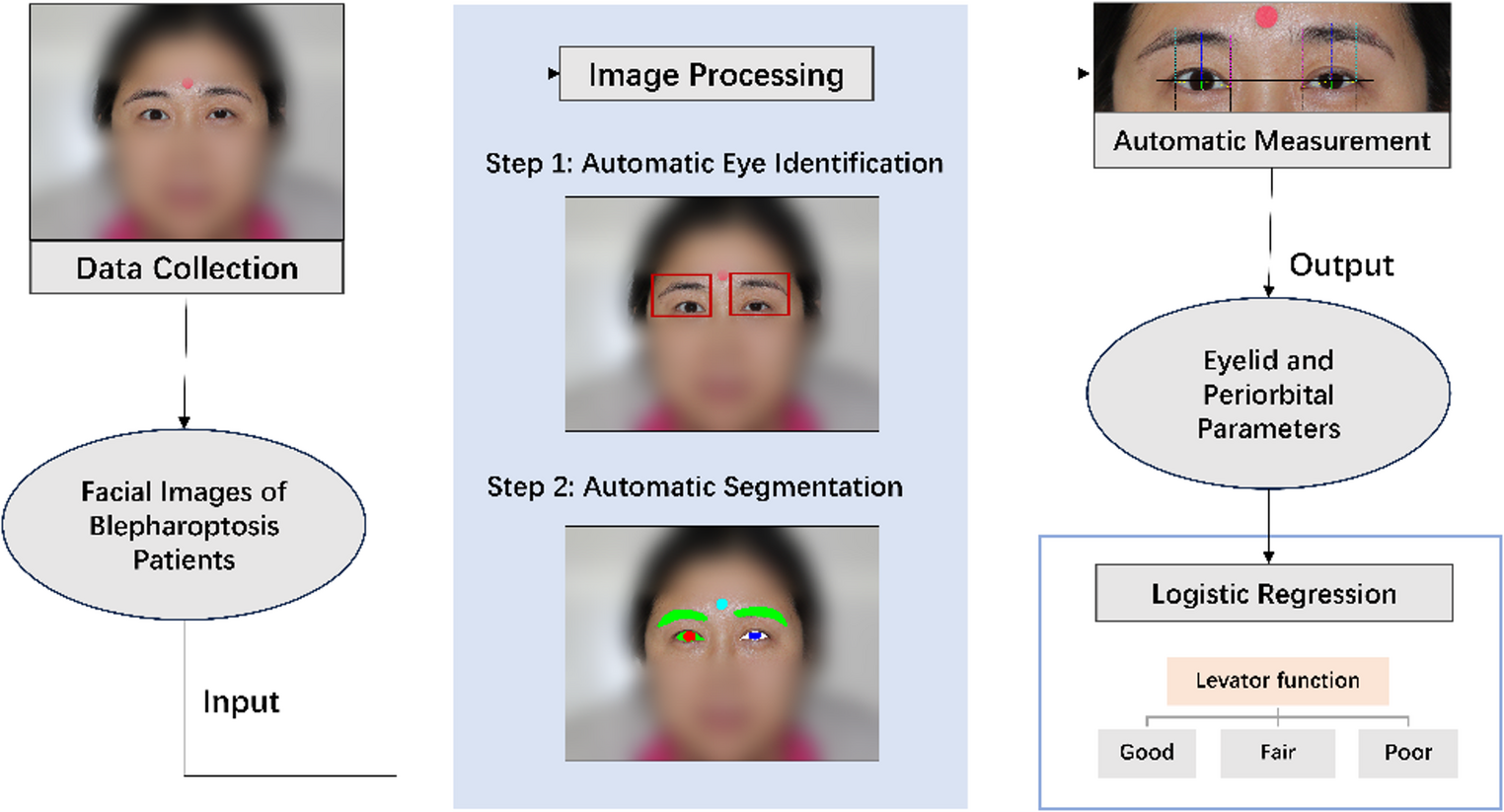
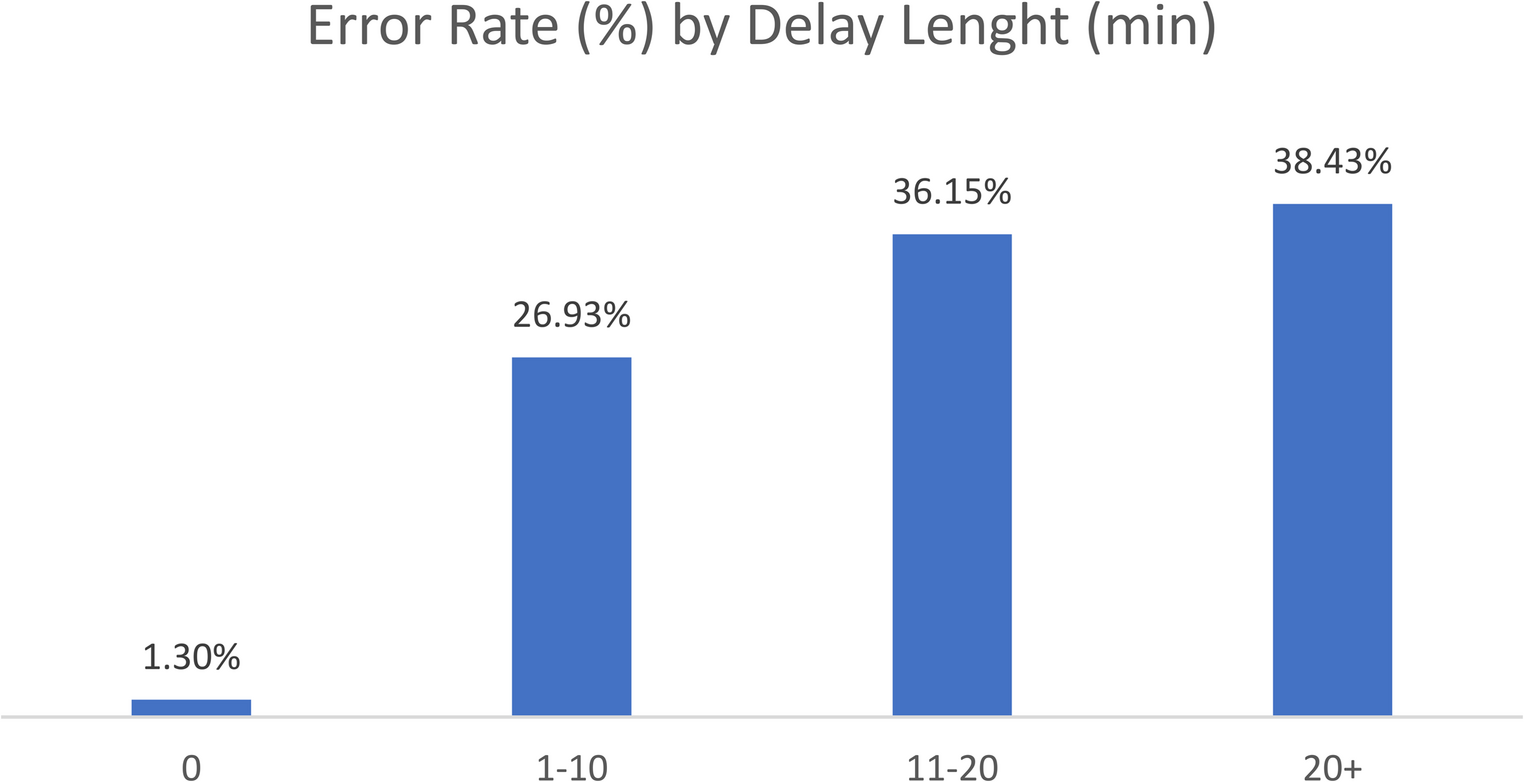


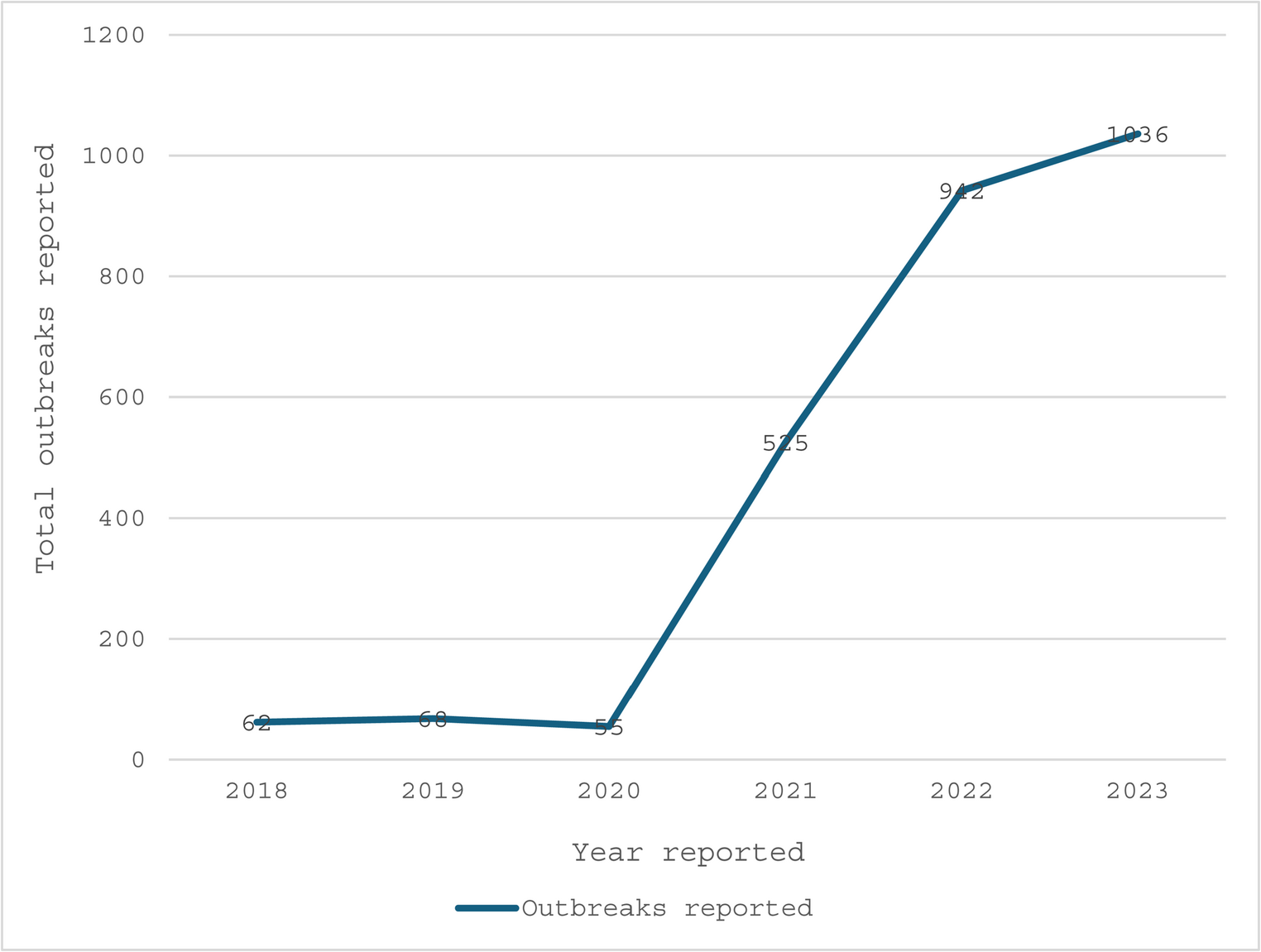



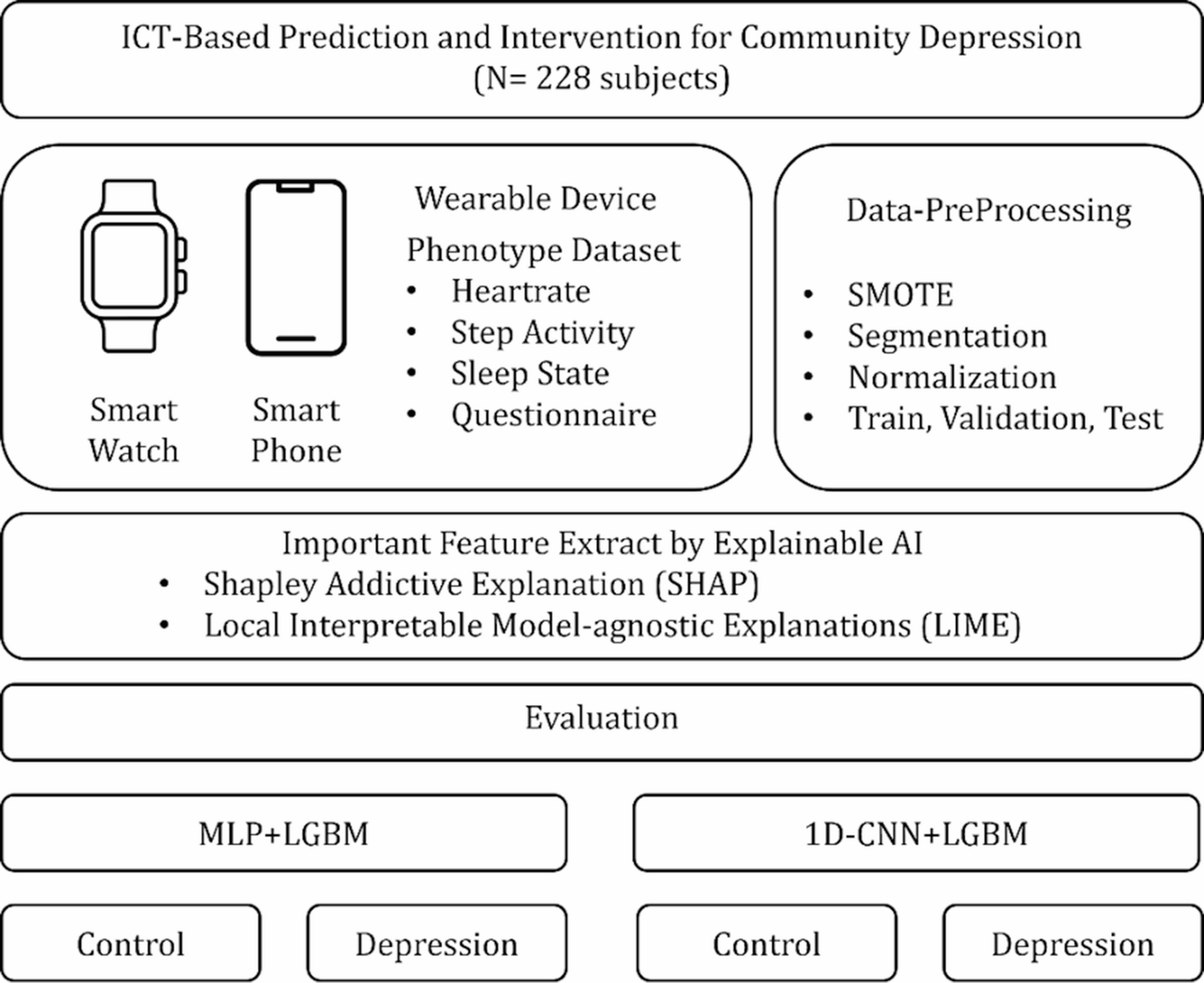

This section details our approach to comorbidity extraction from unstructured clinical text (see Fig. 2). We first formalize the problem and notation, then present three complementary classification paradigms–flat binary, two-level hierarchical, and a LangGraph-based multi-agent variant–that operate over a selected comorbidity taxonomy. We describe prompting schemes and agent orchestration used to elicit consistent decisions, and we define objective functions that balance predictive accuracy with hierarchical consistency. Finally, we outline extraction settings, model choices, and implementation details that enable reproducible application to sleep-medicine narratives.
Fig. 2
Pipeline for comorbidity extraction from historical diagnostic protocols in the Bern sleep-wake registry. Sleep-disorder related ICD categories were mapped into flat and hierarchical structures and provided as prompts to LLMs (Mistral-24B (Instruct-2501), Rombos-14B, Sombrero-14B). Model outputs include binary predictions (True/False) for each comorbidity, together with a Confidence score (CS), which are derived from token probabilities and indicate the model’s internal confidence (0–100%) in the given decision
Problem Setup and NotationWe formulate comorbidity extraction from unstructured clinical text as a multi-label classification task. Let:
\(x \in \mathcal \): an input text (e.g., a medical report for diagnosis of sleep disorders)
\(C = \\): a predefined set of \(n\) comorbidities organized according to the selected taxonomy
Each comorbidity \(c_i\) defines the binary classification task: is \(c_i\) present in \(x\)?
The ground truth label vector is defined as:
$$\begin \textbf = (y_1, y_2, \dots , y_n) \in \^n \end$$
where
$$\begin y_i = \left\ 1 & \text c_i \text \\ 0 & \text \end\right. \end$$
Model SelectionFor all classification paradigms, we employ LLMs as the underlying decision engines. Three complementary instruction-tuned models are evaluated:
Mistral-24B (Instruct-2501): a state-of-the-art open-weight model with strong performance across general-purpose instruction-following benchmarks. Its larger parameter count provides high capacity for nuanced medical language understanding.
Rombos-14B: a mid-sized Qwen LLM optimized for efficiency, enabling practical deployment while still maintaining competitive performance in specialized domains.
Sombrero-14B: a domain-adapted variant with improved robustness on long and heterogeneous narratives, making it particularly suitable for complex sleep-medicine reports.
The combination of a large-capacity model (Mistral-24B) and two efficient 14B-parameter models (Rombos-14B and Sombrero-14B) allows us to systematically investigate trade-offs between accuracy, interpretability, and computational cost in clinical text classification.
Classification ParadigmsWe explore three classification paradigms for framing the comorbidity extraction task using LLMs, all based on the same inputs and comorbidity taxonomy: (1) flat binary classification, (2) two-level hierarchical classification, and (3) LangGraph-based multi-agent classification.
Each paradigm relies on the same input text and predefined taxonomy but differs in how predictions are structured and dependencies between categories are handled. The flat approach treats each comorbidity as an independent binary decision, the two-level hierarchical approach enforces conditional branching between parent and child categories, and the LangGraph multi-agent approach generalizes this hierarchy into a modular graph of interacting LLM agents.
Flat Binary ClassificationFor each comorbidity \(c_i\), define a prompt:
$$\begin }(x, c_i) = \text c_i \text + x . \end$$
The LLM returns a textual response:
$$\begin r_i = }\!\big (}(x, c_i)\big ). \end$$
Map this response to a binary prediction \(\hat_i \in \\) via:
$$\begin \hat_i&= \left\ 1, & \text r_i \in \mathcal _},\\ 0, & \text r_i \in \mathcal _}, \end\right. \\ }\\ \mathcal _}&= \, \text , \_\_''}\},\\ \mathcal _}&= \, \text , \_\_''}\}. \end$$
Two-Level Hierarchical ClassificationLet the comorbidities be organized into a two-level hierarchy:
Ground-truth labels:
$$\begin \textbf^&= \big (y^_1, \dots , y^_m\big ) \in \^,\\ \textbf^_i&= \big (y^_, \dots , y^_\big ) \in \^. \end$$
Step 1::Top-level prediction.
$$\begin r^_i = }\!\big (}(x, c^_i)\big ), \qquad \hat^_i = \left\ 1, & \text r^_i \in \mathcal _},\\ 0, & \text r^_i \in \mathcal _}. \end\right. \end$$
Step 2::Subcategory prediction (conditional). If \(\hat^_i = 1\), then for each \(j \in \\):
$$\begin r^_ = }\!\big (}(x, c^_)\big ), \qquad \hat^_ = \left\ 1, & \text r^_ \in \mathcal _},\\ 0, & \text r^_ \in \mathcal _}. \end\right. \end$$
Otherwise, set \(\hat^_ := 0\) for all \(j\).
Final prediction vector. Let \(d = m + \sum _^ n_i\). The concatenated prediction is
$$\begin \hat} = \big (\hat}^, \hat}^_, \dots , \hat}^_\big ) \in \^. \end$$
LangGraph Multi-Agent ClassificationLangGraph-based multi-agent classification leverages the same hierarchical taxonomy but introduces modularity via explicit computation graphs:
Agents: modular LLM functions operating on \(}(x,c)\).
Graph: a computation graph that routes between top-level, subcategory, and contradiction-resolution agents.
Graph execution.
1.TopCategoryAgent: produces \(\hat^_i\) for each \(c^_i\).
2.SubCategoryAgents: if \(\hat^_i=1\), activate agents for \(C^_i\) to obtain \(\hat^_\).
3.ResultJudger: inspects \(\^_i\}\) and \(\^_\}\) to detect contradictions (e.g., child true but parent false).
4.ContradictionSolver: resolves conflicts with prompt- or rule-based logic.
Output.
$$\begin \hat} = f_}(x; G, A) \in \^, \end$$
where \(G\) is the graph structure and \(A\) the agent library.
Objective FunctionsWe use two objective functions to balance predictive performance and hierarchical validity. The Hamming loss measures overall error rate across main and subcategories, while the hierarchical consistency penalty discourages logically inconsistent predictions.
Extraction SettingsTwo settings are considered for comorbidity extraction:
Top-level ClassificationPredicts the presence or absence of each of the six main comorbidity categories:
Ischemic stroke or transient ischemic attack
Diabetes (any type)
Dyslipidemia
Hypertension
Atrial fibrillation (any type)
Sleep-disordered breathing
Two-Level Hierarchical ClassificationIf a main category is detected, additionally identify specific subcategories. For example:
Ischemic stroke: Cerebral ischaemia, Transient ischaemic attack, etc.
Diabetes: Type 1 diabetes mellitus, Type 2 diabetes mellitus
Sleep-disordered breathing: Obstructive sleep apnoea, Central sleep apnoea, etc.
Hierarchical Prompting StrategiesDesigning effective prompts is central to achieving accurate and interpretable LLM predictions in hierarchical classification tasks. In this section, we outline different prompting strategies and analyze their trade-offs in terms of complexity, number of LLM calls, and suitability for various hierarchy depths (Table 1). We further illustrate how domain-specific multi-shot examples can guide the model toward consistent recognition of both top-level categories and fine-grained subtypes in sleep medicine comorbidity extraction.
Table 1 Comparison of hierarchical prompting strategiesMulti-Shot Prompt Design for Comorbidity ExtractionWe use multi-shot prompting with realistic examples related to sleep disorder comorbidities. The prompts are designed to teach the LLM how to recognize both top-level conditions (e.g., Sleep-disordered breathing, Cardiovascular disease) and specific subcategories (e.g., Obstructive sleep apnoea, Atrial fibrillation).
Agreement and Consistency MetricsFor each document d and parent category p, let the top-level agent output be \(\hat^)}_ \in \\). Let the post-solver OR-merge of all child agents under p be
$$\begin \hat^)}_ \;=\; \max _j \hat^)}_ \in \. \end$$
We evaluate agreement between the parent prediction and the merged children using Cohen’s \(\kappa\) and percent agreement [29], and we quantify hierarchical consistency using Hierarchical Consistency Rate (HCR) and Contradiction Resolution Efficacy (CRE).
Cohen’s \(\kappa\) (Parent vs. Child OR)Form the \(2\times 2\) table over all (d, p) pairs:
$$\begin \begin & \hat^)}_=1 & \hat^)}_=0 \\ \hline \hat^)}_=1 & a & b\\ \hat^)}_=0 & c & d \end \quad \text n=a+b+c+d. \end$$
Percent agreement is \(p_o=\tfrac\) and the expected agreement is
$$\begin p_e=\Big (\tfrac\Big )\Big (\tfrac\Big ) + \Big (\tfrac\Big )\Big (\tfrac\Big ). \end$$
Then
$$\begin \kappa \;=\; \frac. \end$$
Hierarchical Consistency Rate (HCR) Define a contradiction when the child OR is positive but the parent is negative. With N the number of (d, p) pairs,
$$\begin \textrm \;=\; 1 \;-\; \frac\sum _ \textbf\!\left\^)}_=1 \;\wedge \; \hat^)}_=0\,\right\} , \end$$
where contradictions are computed on post-solver predictions.
Contradiction Resolution Efficacy (CRE). If pre-solver child predictions are available, define
$$\begin C_}=\sum _\textbf\!\left\^)}_=1 \;\wedge \; \hat^)}_=0\,\right\} ,\\\quad C_}=\sum _\textbf\!\left\^)}_=1 \;\wedge \; \hat^)}_=0\,\right\} . \end$$
The efficacy of the solver is
$$\begin \textrm \;=\; \frac} - C_}}}} \end$$
(Only when pre-solver predictions are logged; undefined if \(C_}=0\)).
LangGraph ReAct Agent WorkflowThe LangChain ReAct agents in this implementation serve as modular classification tool for clinical comorbidity detection. Each ReAct agent is initialized with a specialized prompt tailored to a particular top-level comorbidity category (e.g., atrial fibrillation) or its subtypes (e.g., paroxysmal, persistent) which has been illustrated in Fig. 3. These agents take clinical text as input and produce structured True/False outputs or condition lists, depending on the classification level. By encapsulating each decision process in a separate agent, the system maintains explainability, prompt specialization, and easy extensibility–new categories or conditions can be added simply by instantiating new tools with adapted prompts.
Fig. 3
Example of LangGraph multi-shot classification
In the LangGraph implementation, the overall workflow is structured into two hierarchical stages: top-level and subcategory classification. The pipeline begins by evaluating the presence of each high-level comorbidity class through a sequence of top-level agents. For any category determined as True, LangGraph conditionally routes execution to a second stage containing subcategory agents specific to that parent (see Fig. 4). Each sub-agent confirms or denies the presence of its respective condition in the clinical text while assuming the parent context is relevant. This architecture enables efficient, interpretable multi-shot reasoning with controlled branching and parallelizable decision trees, well suited for large-scale medical text classification tasks.
Fig. 4 Ablation Test and Experimental Settings for Two-Level Multi-Agents
Ablation Test and Experimental Settings for Two-Level Multi-AgentsWe ablate the multi-agent graph to quantify the contribution of (i) early judgment/filtering, (ii) post-hoc reconciliation of parent–child disagreements, (iii) hierarchical structure vs. a flat classifier, and (iv) parent\(\rightarrow\)child context forwarding. We report macro-F1 (top-level), hierarchical consistency (HCR), and cost (tokens per document), and we keep the test split, prompts, few-shot examples, and decoding parameters fixed across variants.
All runs use the same documents, the same instruction and examples, and the same base model (Mistral-24B (Instruct-2501)). For hierarchical variants we execute a parent agent for each of the six comorbidity categories and, when applicable, sub-agents for their subtypes. Agreement and consistency are computed as defined in Section“Multi-Shot Prompt Design for Comorbidity Extraction” (Cohen’s \(\kappa\), HCR, CRE). Cost is measured as total prompt + completion tokens per document aggregated over all agent calls.
The following variants of settings were tested:
Full LangGraph (baseline). Parent agents gate their corresponding sub-agents; intermediate outputs are checked by ResultJudger; child outputs are merged and reconciled by the ContradictionSolver. Parent evidence (decision + supporting snippet) is forwarded to the children (Context Forwarding). Final labels comprise parent predictions and post-solver child OR.
– ResultJudger. Identical to baseline except the early judgment/filter node is disabled. Downstream sub-agents execute as gated by the parent, and contradictions are still reconciled by the solver. This isolates the effect of early pruning on HCR and macro-F1.
– ContradictionSolver. Identical to baseline except the reconciliation stage is removed. Parent and child outputs are taken as-is; any parent\(=\)0 / child-OR\(=\)1 inconsistencies remain unresolved. This isolates the contribution of post-hoc consistency.
Flat (matched cost). A single-pass, non-hierarchical classifier predicts all top-level categories and subtypes jointly (no gating, no solver, no context forwarding). To make comparisons fair, we cap the average token budget to match the baseline (matched cost).
Two-Level (no solver). Hierarchical with parent gating and child sub-agents, but without the solver. Useful to separate the benefits of structural gating from those of reconciliation.
No Context Forwarding (Atrial fibrillation (AF) subtypes). Same as baseline but the AF sub-agents receive no parent decision or evidence (no forwarding). This tests the role of parent context in fine-grained AF subtype discrimination; other categories remain unchanged.
For each variant, we compute macro-F1 at the top level, HCR from parent vs. post-solver child-OR (or n/a for the flat model), and tokens/document over all model calls. When pre-solver child predictions are logged, CRE is additionally reported to quantify the fraction of contradictions eliminated by the solver.
Evaluation MetricsModel performance was evaluated using accuracy, precision, recall, and F1 score, reported as both macro- and micro-averaged metrics across comorbidity classes. Macro-averaged metrics were computed by calculating each metric independently for every comorbidity class and then averaging them with equal weight, thereby reflecting per-class performance and sensitivity to class imbalance. Micro-averaged metrics were computed by aggregating true positives, false positives, and false negatives across all classes prior to metric calculation.
Comments (0)