
Remember me






This work introduces our adoption of a proven vision-language model (VLM) architecture that we customized for multi-task deep learning in endoscopic ENT surgery. Data were collected and annotated to align sequential surgical artifacts, including endoscopic frames, surgical keywords, and report sentences, into a vision-language dataset. The VLM employs an encoder-decoder structure, leveraging pre-trained and fine-tuned encoders. For the multi-task dataset, three different task-specific datasets were combined. We previously trained deep learning models on subsets of data from the same database of functional endoscopic sinus surgery (FESS) procedures and extended them to now cover the same video database (n = 30) consisting of 16 h of ENT procedures. The result was a dataset, for which each datapoint included an associated multi-label class (task 1), a current and future anatomical description (task 2) as well as the most recent part of a surgical report and a keyword (task 3). In the following sections, the specific tasks and task losses are described in detail followed by details on the combined dataset.
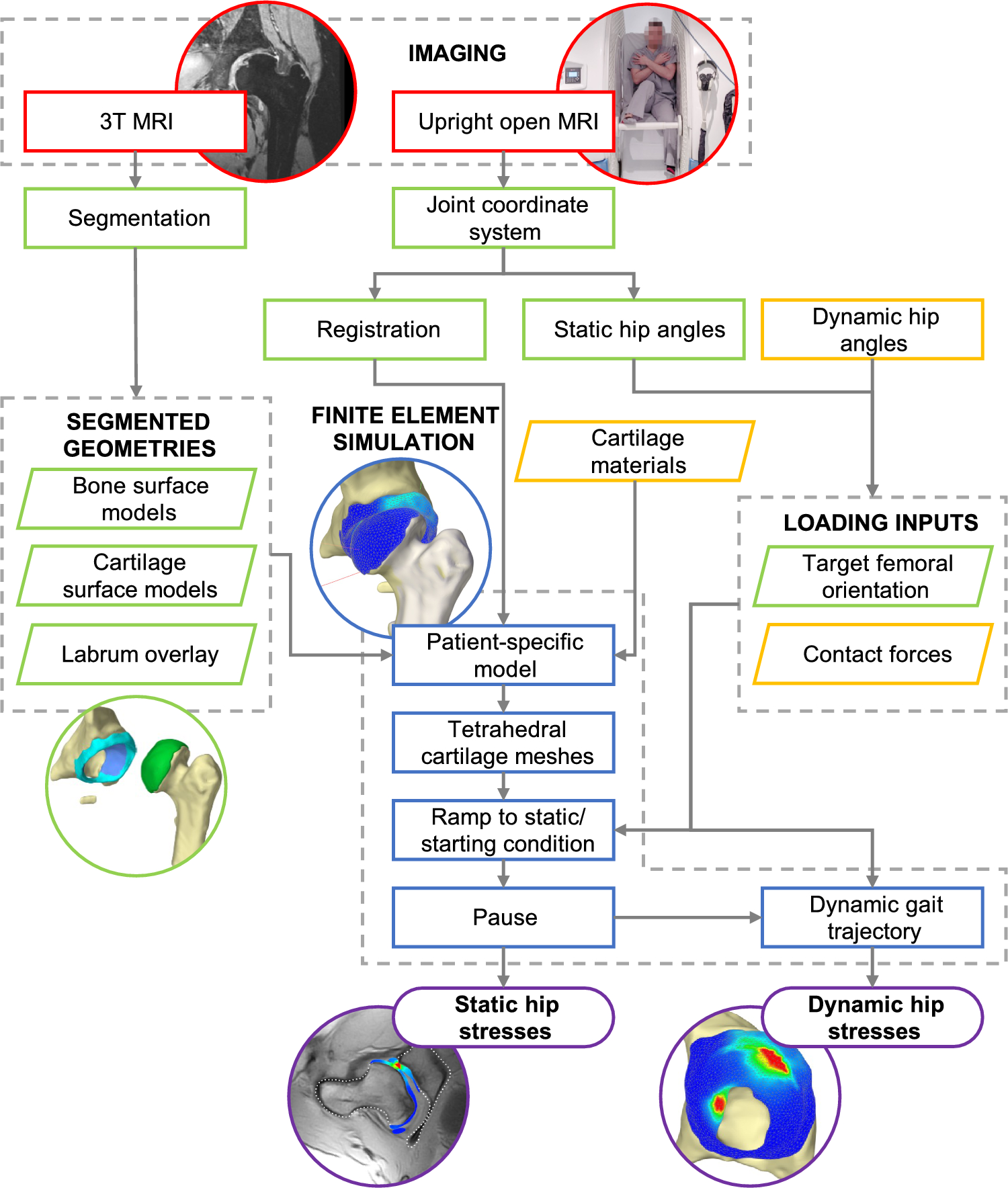
Multi-task dataset preparation and statisticsOur study relies on a single, fully synchronized dataset assembled from three previously independent studies. We first selected thirty video recordings of FESS that together span roughly sixteen hours. Using the sentence‑level annotation protocol introduced in our work on language‑based workflow translation [19], we segmented each recording into “activities”, contiguous time windows in which one anatomical configuration remained stable; this yielded 4 322 annotated activities. The resulting label distribution is markedly skewed. The middle nasal meatus, middle nasal concha and uncinate process each appear in more than 20% of all annotated frames, whereas the anterior and posterior ethmoidal arteries are present in fewer than 10%. Within every activity we sub‑sampled the video at five frames per second and, following our image classification study [20], assigned to each frame a 16‑dimensional binary vector indicating the presence of the middle nasal meatus, uncinate process, and fourteen additional landmarks. To add natural‑language context, we drew on the 1197‑sentence commentary corpus from our earlier report‑generation paper [13]. Three senior ENT surgeons retrospectively followed each procedure recording and marked the first and last frame in which the report sentence accurately described the intra‑operative scene and also assigned a distinct keyword for this step. For any video frame t we thus obtained (1) the binary landmark vector, (2) the natural‑language landmark description originating from the workflow annotation, and (3) the “current” report sentence together with its keyword as well as the cumulative report history up to t. Frames for which one of these channels was missing were discarded. The resulting dataset comprises approximately 130.000 frames, each paired with structured landmark labels and free‑text commentary. This alignment enables the three target tasks of our study at the same temporal resolution (Figs. 1, 2).
Fig. 1
Overview of a data point in the multi-task dataset. Task-specific data is differently colored. Anatomical landmarks are additionally indicated as regions-of-interest in endoscopic images and are not part of the dataset
Fig. 2
Overview of the label distribution across the sampled 130.000 image frame of the dataset (left) and text parameters for the structured and natural language datasets (right). Distribution percentages exceed 100% as multiple labels can be present at the same time during observations
Task definitionsTask 1: Image ClassificationThis task is a multi-label classification problem, where each endoscopic image is associated with one or more anatomical landmarks that can be observed. It can also be interpreted as a form of image captioning of the endoscopic movement in situ. Endoscopic images were annotated with defined labels from [12]. Each annotation contained an arbitrary combination of 16 prominent landmarks that appeared alone or in combination during annotation.
The task was then to classify the multiple labels that are present. Let \(_ :I \times T \to C\) be the classification function that takes images \(I\) of a recorded video at a specific time T to produce classifications \(C\) with \(C=\_,_\right),c\left(_,t}_\right),\dots |_\in T,_\in I\}\) where \(c(i,t)\) are individual class vectors. Using the approach in [13], we construct an ordered set of labels \(L\) of our annotated landmarks with\(L=\_,_, \dots , _\)}. The class vector \(c(i,t)\) is then constructed with binary encoding as.
$$c\left(i,t\right)=[_,_, \dots , _],$$
Where
$$_=\left\1, if _ is present in i(t)\\ 0, otherwise\end\right.$$
A classifier would then be optimized to output a candidate prediction \(\widehat(i,t)\) that minimizes the average binary cross-entropy loss:
$$}_}\left(c,\widehat\right)=\frac\sum_^-(_\text}_+\left(1-_\right)\text(1-}_)$$
where \(_\) and \(}_\) are the \(^}\) component of the target and prediction vectors. The loss calculation is performed in the same way as image segmentation is done but with only 16 pixels to process.
Task 2: Landmark PredictionThis task was introduced to predict future anatomical landmarks from annotated videos of ENT endoscopic surgeries. Endoscopic videos were annotated where a specific landmark or combination of landmarks was observed. Using the annotation scheme in [12], each activity corresponds to video segment of arbitrary duration and has a sentence-level description \(_\) in the structure:
$$_= \left(Step Count, Main Cavity, Landmark Group, Landmarks , Movement Direction\right)$$
To make use of the embeddings from the text encoder, we translated the used taxonomy into a natural language form, e.g., turning the concept concha_nasalis_media_group into “group of the medial nasal concha” or Uncinate_process_of_ethmoid into “Processus uncinatus”. The task is then to predict from a current natural language description where the endoscope will most likely move toward. We chose a sequence-to-sequence style approach and constructed description pairs \(\__},__}),__},__}),\dots \}\). This concept is based on work about transfer learning of text-to-text models like T5 [14]. The model produces description words by maximizing the conditional probability:
\(_=\left[_,_, \dots , _\right]\) and \(_=argmax \prod_^p\left(}_|_\right)\)
with \(_\) being the \(^}\) word in the description sentence and \(p\left(}_|_\right)\) being a probability for a candidate word \(}_\) of the final selected description word \(_\). This auto-regressive word-by-word behavior is essentially a probability distribution of word relations.
The current procedure duration \(t\) and the current observation duration were added as decimal numerals to address data synchronization. With the time-dependency, we can specify a prediction function \(_ :_\times T \to _\) with
$$_\left(t+1\right)=argmax \prod_^p\left(}_(t+1)|_(t+1)\right)\text$$
$$_\left(t+1\right)=_\left(_\left(t\right)\right)= _\left(argmax \prod_^p\left(}_(t)|_(t)\right)\right).$$
Here, \(}_\left(t\right)\) and \(}_(t+1)\) depict the conditional probability of having the complete descriptions \(_\left(t\right)\) and \(_\left(t+1\right)\).
The text decoder in our VLM produces the words of \(_\left(t+1\right)\) in succession as described above with a starting token and based on the embedding of \(_\left(t\right)\) through a text encoder. The model is optimized on this prediction function using the KL divergence loss:
$$}_}\left(__}||__}\right)=_^__}\left(_|_,\dots ,_\right)log\frac__}\left(_|_,\dots ,_\right)}__}\left(_|_,\dots ,_\right)}$$
Here, \(_, \dots , _\) is the predicted sequence of words of the decoder model, \(__}(w)\) and \(__}(w)\) are the ground truth and predicted conditional probabilities or negative log-likelihoods of the word sequence. The loss will be lower when the negative log-likelihood of \(__}(w)\) for each predicted word resembles that of \(__}(w)\).
Task 3: Report GenerationThis task assumes a language model can generate text sections of a surgical report based on spoken keywords during surgery. In this way, a keyword is combined with a partial report as the context window and parsed into an encoder-decoder model to output the next report sentence [13]. Let a dataset contain report sentences \(_\) of a surgical report in the form of natural language text. For our task then exists a text generation function \(_ :H\times K\times T \to _\) than can procedure surgical sentences \(_\) at times \(T\) with keywords \(K\) and the available context \(H\) such that:
$$_(t)=_(k}_,_|_\in K, _\in H,t\in T)$$
Here, a surgical sentence \(_\left(t\right)\) at the duration \(t\) of a procedure is generated with uttered keywords \(_\) and the accumulated context \(_\) with
$$_=\_,__}\right),\left(_,__}\right),\dots ,(_,__})$$
The context \(_\) can be understood as a set of ordered pairs of keywords and report sentences of all previous timesteps up to \(t-1\) in a procedure. Both \(_\) and \(_\) are used together as one string sequence as part of the text encoder input. During training, we use a fixed context window length of the 250 most recent tokens. We optimize a model for this task using a variation of cosine similarity loss with focal penalization of high similarity between the target and candidate sentences \(_\left(t\right)\) and \(}_\left(t\right)\) with
$$}_}\left(_,}_\right)=}_\left(t\right)\right)\cdot e(_\left(t\right))}}_(t)\right)\right|\left|e(_\left(t\right))\right|}\right) }^$$
Here, \(e\left(}_\left(t\right)\right) \texte(_\left(t\right))\) represent the embedding vectors of the target and candidate sentences that we calculate with a pre-trained text encoder (see 3.4.1). The cosine similarity is penalized using \(\gamma \) with values between 1 and 2. For our multi-task approach, we also use the keywords as the starting tokens at the beginning of the generation of \(}_\left(t\right)\).
Comments (0)