
Remember me

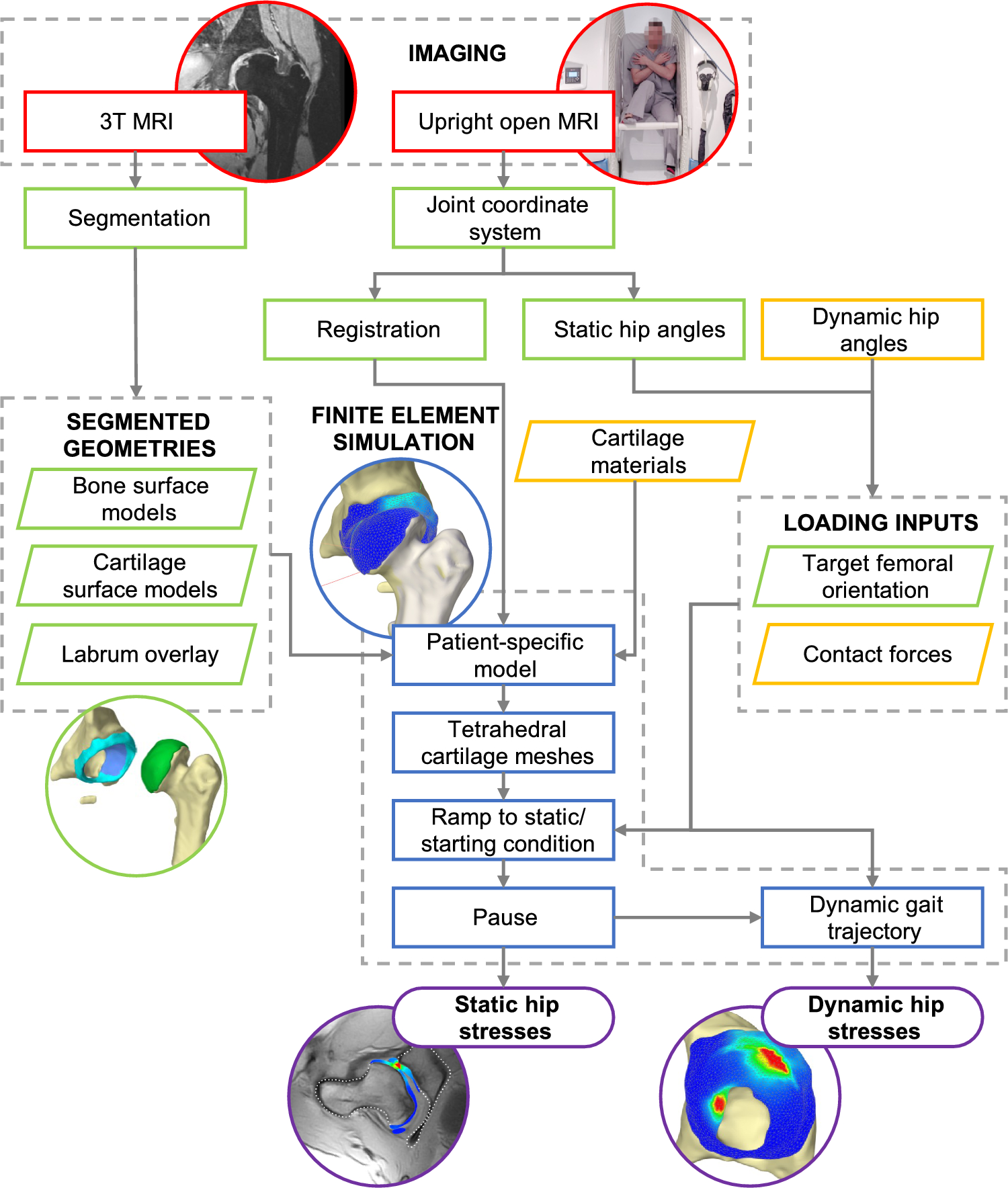





The base network used in this work for segmentation of biomedical images is a 2D U-Net from Ronneberger et al. [17], which has been slightly adapted by zero padding and batch normalization. The architecture consists of 5 stages, in each of which 2 successive convolution operations (3x3 kernels) are performed. In every stage, a rectified linear unit (ReLU) activation function and batch normalization are used [18]. Since the convolution leads to a reduction of the tensor size, an additional zero padding is added. The structure, number of feature maps, image size, and applied operations in every stage of the down- and up-sampling path are shown in Fig. 1. The dice loss is used as loss function. For the optimizer, the adaptive moment estimation (Adam) method with an initial learning rate of \(10^\) is used.
Fig. 1
Segmentation network structure
Augmentation strategiesFor generalization of the DL network, data augmentation is randomly performed before each training epoch to avoid overfitting. For the augmentation process, the following 4 approaches are used and combined with each other:
BigAugThe BigAug approach by Zhang et al. [13] is used as an approach for basic data augmentation. The approach is implemented with the albumentations and scikit-image libraries.
Extensive Augmentation (ExAug)To extend and adapt the previously described approach, the ExAug approach is created. The application order, application strength, and probability are shown in Table 1. In order to ensure a realistic adjustment and an extensive diversity of the augmented data, all transformation ranges (minimum and maximum) of the BigAug approach were analyzed and adjustments were made on this basis. Furthermore, the ExAug approach was optimized for the combination with intensity-based augmentations. This approach was also implemented using the albumentations and scikit-image libraries.
Table 1 ExAug transformation with application strength and probability, listed in application order (No. 1 to No. 14)StyleAugFor intensity augmentation, the pipeline of Hesse et al. [14] with the style transfer algorithm of Jackson et al. [12] was adopted. The associated specifications were adopted (probability = 50 %, weighting factor \(\alpha \) = 0.5 to control the strength of the style embedding). The pipeline was applied as described in section 2.2. For the input, 1 channel layered images were expanded to 3 channels by copying the first channel. Each slice was stylized individually. As in Hesse et al., the stylized output images were transformed back into 1 channel images using the PyTorch grayscale transformation.
Colormap Augmentation (CmapAug)As an alternative to the style augmentation, a new, more efficient method is proposed and investigated. Although a preliminary variant for 3D cases has been shortly discussed in previous work [19], to the best of our knowledge such a method has not yet been published in any peer-reviewed paper with this degree of analysis. By a simple colormap transformation, the grayscale images are transformed into RGB images. In our work, colormaps are used to align the DL model to abstract from intensity-based features and obtain more structural contextual information. By performing the complete model building and analysis process in the colorspace (model training, validation, and testing), modality-specific differences of the various imaging methods can be neglected and an improvement of the segmentation accuracy in the cross-modality scenario can be achieved. With predefined colormaps from Matplotlib, a specific color value is assigned to each gray value intensity. As shown in Fig. 2, no additional calculation is needed for this process, so the gray value is simply assigned to a specific RGB value, given by the chosen colormap.
Fig. 2
Colormap transformation method
Fig. 3
Selected colormaps and exemplary transformed CT slices
For augmentation, a colormap package of 32 different colormaps is manually selected. The preselection of the colormap package is based on two steps. First, colormaps that lead to a loss of image information due to the specific color code (assignment of multiple gray values to the same color values) were removed. This applies to all qualitative colormaps, as well as the miscellaneous colormaps ‘flag’ and ‘prism.’ Next, all colormaps were applied to the image data, to check the extent to which the data were adjusted. Based on this, the colormaps that generated minor changes in the image data were removed. This applies to all diverging colormaps, the cyclic colormaps ‘twilight’ and ‘twilight_shifted,’ all sequential colormaps, the perceptually uniform sequential colormap ‘cividis,’ and the sequential2 colormaps ‘binary,’ ‘gist_yarg,’ ‘gist_gray,’ and ‘gray.’ Figure 3 shows the color chart of all 32 colormaps and 4 exemplary transformed CT slices. One of the 32 colormaps is randomly selected for each input image during training. Due to its simplicity, it is not necessary to use GPUs for the colormap transformation, as opposed to style transformations. The probability of augmentation is set to 100 %. Through this, the training is performed completely in the RGB space. To reduce the gap between training and testing data, the validation and testing data are also transferred into the RGB space. For this purpose, a predefined colormap of the 32 maps is used for the whole validation and test data, so that all these images are processed under the same conditions. The selection of this colormap is based on experiments with each colormap individually. For these experiments, a U-Net was trained with all 32 maps for augmentation, validated with one specific colormap after each training epoch, and tested with the same colormap. The colormap with the best performance was chosen (gnuplot2, Dice Score: 83.1 %). The random transformation of the input images should lead to a continuous change of the image intensities, so that only the image structures are learned.
Combination of approachesSince the two augmentation approaches BigAug and ExAug and the two augmentation approaches StyleAug and CmapAug are, respectively, similar in their structure and application goal, one of each pair is combined with each other. Considering also the 4 augmentation approaches in an individual manner, a total of 8 augmentation strategies will be investigated as ablation studies.
DatasetsFour different datasets from multiple vendors and scanners were used to evaluate the various data augmentation approaches. The main publicly available datasets are from the ‘Combined Healthy Abdominal Organ Segmentation (CHAOS) Challenge’ [20, 21]. The CHAOS datasets can be divided into an MRI (20 healthy patients, a total of 1294 T1, and 623 T2 slices with a resolution of 256x256) and a CT dataset (20 healthy patients, a total of 2874 slices with a resolution of 512x512). For both datasets, images were acquired from different patients. For training the DL network, only one of the two datasets is used (source domain). Testing is performed on the other dataset (target domain). To verify these results, two additional publicly available CT datasets are used. One dataset comes from the database ‘The Cancer Imaging Archive (TCIA)’ [22] (43 healthy patients, a total of 10235 slices with a resolution of 512x512) and the other dataset from the ‘Beyond the Cranial Vault (BTCV)’ challenge [23] (47 cancer or hernia studies patients without tumor in the liver, a total of 5774 slices with a resolution of 512x512). These datasets are only used to test the model (target domain) when trained with MRI data. For all datasets, the ground truth mask of the liver is available.
PreprocessingIn the first step, all outliers in the CT data were eliminated. For this purpose, all intensity values exceeding the value range of the Hounsfield scale [24] were set to the volume’s maximum value within the value range. Subsequently, all image slices (CT and MRI) were set to the value range 0 to 1 using the min-max normalization. As the last step, all input data slices (training, validation, testing) were resized to 256x256, so that all used datasets from different scanners and vendors have the same image size.
Evaluation metricsTwo established metrics are used for evaluation, one of which is widely used as main metric (Dice score) [8, 9, 14, 16]. As the Dice score measures segmentation performance only by the overlap ratio between prediction and ground truth, the Hausdorff distance is additionally used to indicate the magnitude of the deviations and thus a measure of the incorrect classifications. During the validation process of each training epoch, the Dice score is used to calculate the compliance of each pixel between the prediction and ground truth for every single image (2D) [25]. For the evaluation, the Dice score and the Gromov–Hausdorff metric (Hausdorff distance) were used. The Hausdorff distance calculates the maximum deviation between the prediction and the ground truth [26]. During the evaluation (testing), the Dice score and the Hausdorff distance are calculated for each patient volume (3D).
Comments (0)