In this section, we describe performance metrics and the dataset used to evaluate TAD-SIE. We describe the baseline algorithms against which we compare our approach and describe the ablation studies done to demonstrate the contribution of each novel component of TAD-SIE. We also provide implementation details of the algorithms and experiments.
Performance metrics
We set target power, \(1-\beta _\), to 80% and target significance level, \(\alpha _\), to 5%, following typical target operating points [1]. We measure power and significance level obtained by TAD-SIE and baseline algorithms following the approach from [14], which simulates many trials under the alternative and null settings and calculates the percentage of trials where the test procedure returns a reject, respectively. Specifically, we simulate a trial under the alternative setting by constructing new control and treatment arms with subjects sampled with replacement from the original RCT’s control and treatment arms, respectively. Similarly, we simulate the null setting by constructing both the control and treatment arms with subjects sampled with replacement from the original RCT’s control arm.
For TAD-SIE, we also report the final arm size and number of iterations that a trial takes in order to characterize TAD-SIE’s efficiency.
Dataset
We evaluate the framework on a real-world clinical phase-3 parallel-group RCT and demonstrate it for a two-arm superiority trial, a design typically adopted in clinical RCTs [1]. We obtained the dataset for a sample trial, e.g., CHAMP (NCT01581281), [15, 16], from the National Institute of Neurologic Disease and Stroke (NINDS) [17]. Additional details can be found in the Appendix: Dataset section.
Baselines
We compare TAD-SIE against two baseline algorithms. Both algorithms implement parallel-group RCTs following a two-arm superiority setup and therefore use the two-sample t-test for independent samples with unequal variances for hypothesis testing [12]. The approaches differ in how they determine the final sample size.
The fixed sample design baseline is a standard approach for study planning that calculates the sample size required for target power and target significance level using Eq. (1), where the ATE \(\delta\) and variances for the control and treatment arms, \(\sigma _^2\) and \(\sigma _^2\), are pre-specified or estimated from a prior study [1, 7]. Since domain knowledge may not be available to appropriately pre-specify these parameters, the baseline implements a small internal pilot study to estimate these parameters [6]. The baseline then conducts an RCT according to the calculated sample size, which is capped at a maximum arm size set by trial constraints [7].
$$\begin n_=\frac^+\sigma _^\right) \left( z_+z_\right) ^}} \end$$
(1)
We also implement a traditional adaptive design that can increase the initial sample size calculated by the fixed sample design strategy in order to increase power. We adopt a TAD based on CP and specifically implement the algorithm from [9], given its simplicity, which we refer to as standard TAD. Specifically, at each interim analysis, it increases the sample size according to the sample size formula when CP is above 50%.
Ablation studies
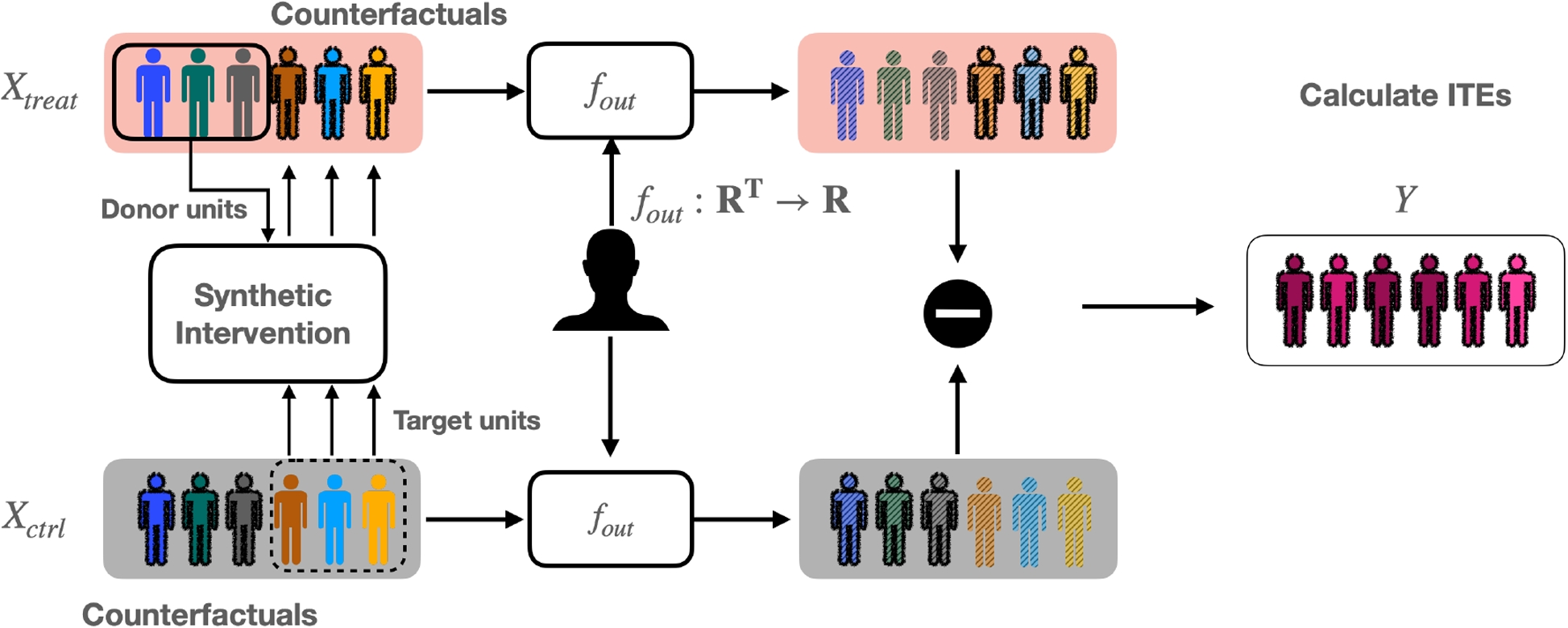
We validate the importance of each component in TAD-SIE using several ablation studies. First, we swap the proposed variance estimation procedure (Algorithm 1) with a naive approach that uses the variance of the ITEs (thereby assuming that the ITEs are i.i.d. [12]). Next, we swap the proposed TAD with a standard TAD [9] to show that an approach implementing a rule for sample size increases, based on control over significance level, will fail to reach the target operating point since increases are rare. Finally, we modify TAD-SIE so that it performs sample size estimation based on standard hypothesis testing instead of SECRETS to show that a TAD designed for a powerful testing scheme is necessary for reaching the target operating point. Additional implementation details for the ablations are presented in the Appendix: Ablations section.
Implementation details
We describe the hyperparameters used by TAD-SIE and the baseline algorithms. Additional experimental and computing details are provided in the Appendix: Implementations details section.
Hyperparameters for TAD-SIE are reported in Table 1. While most hyperparameters can be determined from prior work, step_size_scale_factor is a new hyperparameter introduced by TAD-SIE; hence, we sweep over values over the domain of the hyperparameter in increments of 0.1 to characterize its effect on performance. Hyperparameter details for SECRETS are specified in the Appendix: Implementation details section.
Table 1 Hyperparameters used for TAD-SIE. The "Reference" column lists references that support the choice of the hyperparameter value The baseline algorithms use the same values used by TAD-SIE for \(n_\), \(\alpha\), \(1-\beta\), and \(n_\). For Standard TAD, we set the number of interim analyses to 1 since this is common in practice [7] and perform interim analysis at the initial planned sample size by setting \(t=0.99\) (CP is undefined at \(t=1\)) since this is ideal for assessing whether the sample size can be increased and the amount by which it needs to be increased [7].





Comments (0)