
Remember me

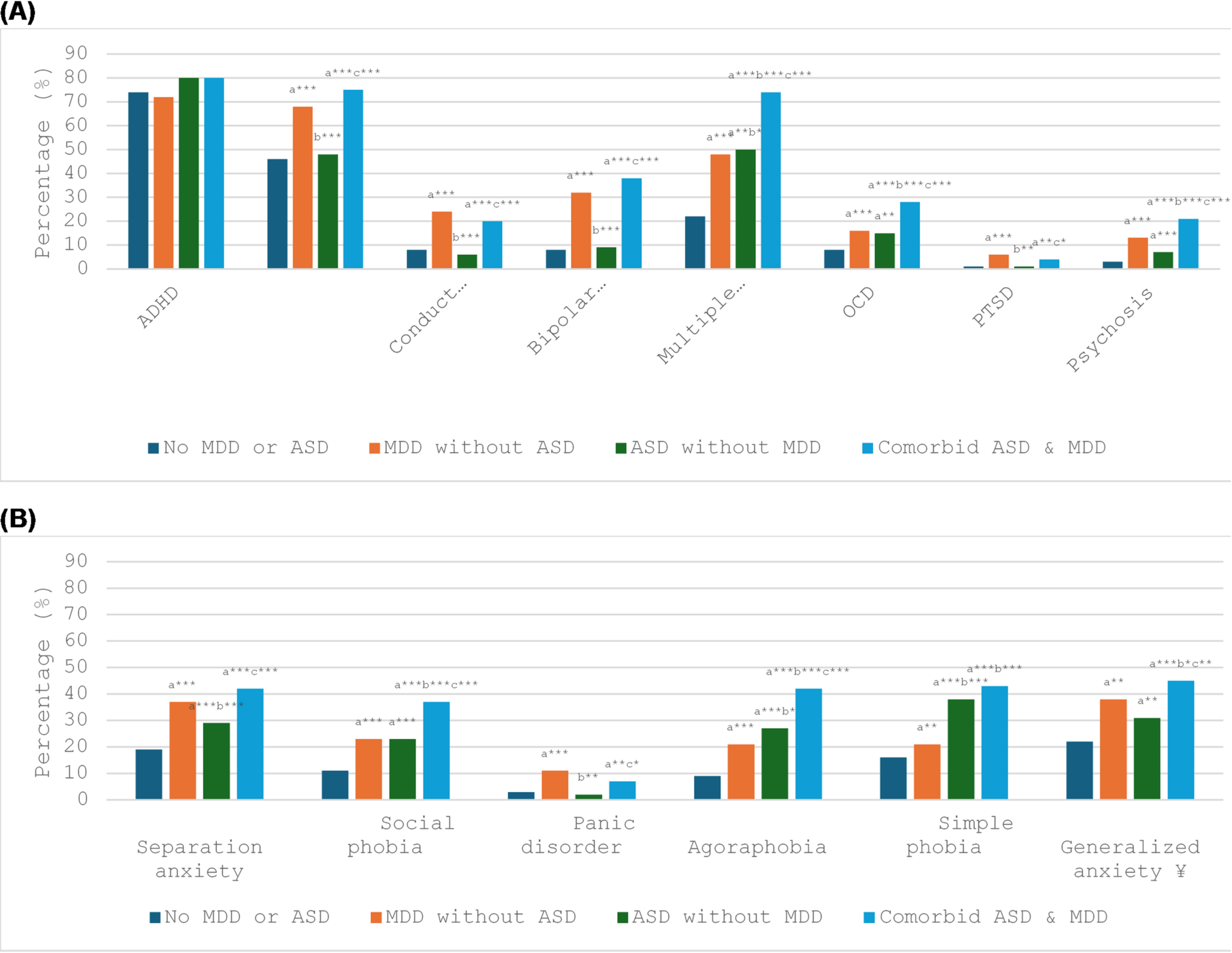
In this section, we analyse the 10 most cited articles from the final database, following to the selection criteria outlined in Sect. 5. A comprehensive overview is shared, highlighting the key areas of interest in the selected articles on the application of AI to diagnose both neurological and mental disorders. First, the most commonly used algorithms in this field will be listed and briefly explained, addressing research question number 5 (RQ5). Next, the metrics used to evaluate the performances of the aforementioned algorithms will be indicated (RQ6). Finally, the primary challenges faced in the selected articles will be discussed (RQ7).
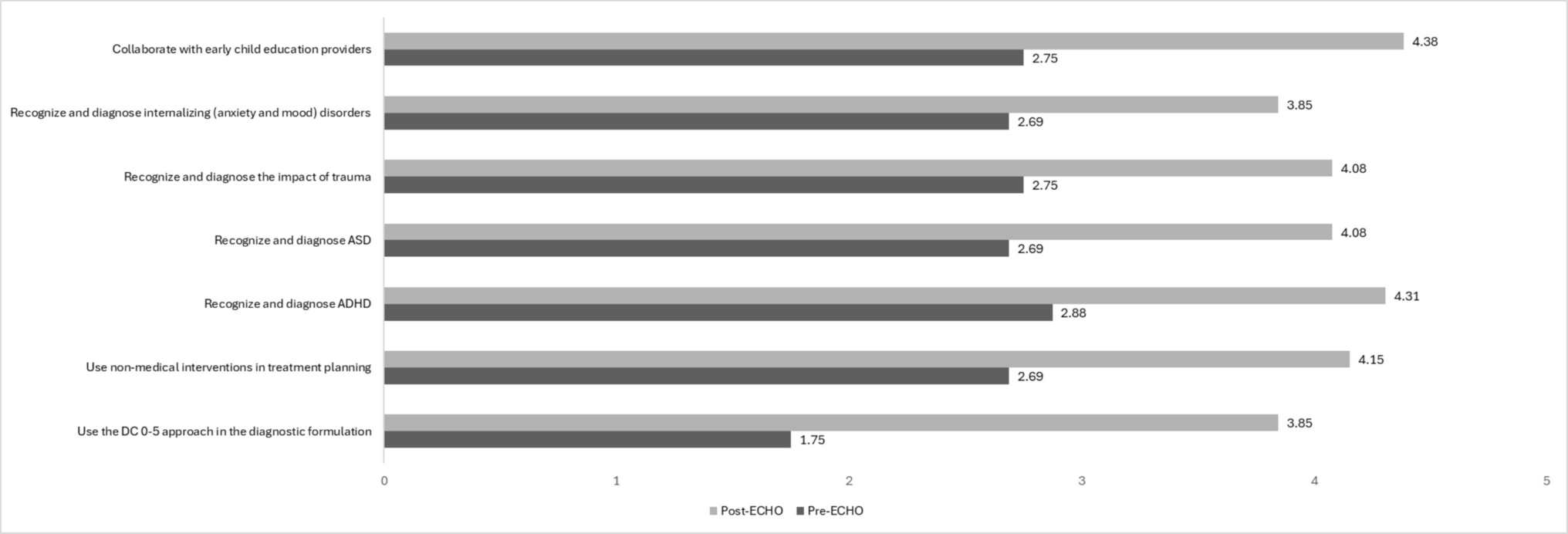
In Fig. 10, the following information is given for each article: the title (first column), the year of publication (second column), the number of citations (third column), the method underlying the proposed technique (fourth column), and the dataset utilised for the analyses (fifth column). Where specific details are not provided, these are marked as “N/A”.
Fig. 10
Schematic summary of the content of the 10 most cited papers. The first column contains the title of the articles, the second the year of publication, the third the number of citations, the fourth the model used and the fifth the origin of the datasets used
RQ5Which AI algorithms have been most commonly used to diagnose both neurological and mental disorders?
This research question aims to offer professionals with a clear understanding of the algorithmic techniques applied in this field, as discussed in the selected studies. To this end, the technical aspects of each document are examined, including the algorithms employed and the datasets used. The most frequently employed techniques are outlined below:
Support vector machine (SVM):
SVM is a machine learning algorithm widely used for classification problems due to its simplicity and flexibility. It learns from examples to categorize or classify objects. Basically, the primary goal of SVMs is to determine a Hyperplane that effectively separates data points belonging to different classes. The chosen hyperplane is the one that maximises the distance between the hyperplane and the closest data points from each class. Recently, SVM has been employed to accurately predict diagnosis and prognosis of brain and psychiatric disorders, including Alzheimer’s disease, schizophrenia and depression [36, 37].
Convolutional neural network (CNN):
A CNN is a type of artificial neural networks designed to simulate the human visual process. It consists of artificial neurons that handle inputs through various operations across multiple layers. In particular, it applies convolutional filters to input data to detect features and hierarchically learns more complex patterns through multiple layers. CNNs and are widely used in machine learning due to their numerous applications, such as facial recognition, image and video analysis, handwriting recognition, anomaly detection, drug discovery and voice recognition [38].
Logistic regression:
Logistic regression is a statistical method used to predict binary outcomes (e.g., diseased/ healthy) based on one or more independent variables. It is widely used in healthcare research for decision-making models and disease state prediction. Logistic regression relies on maximum likelihood estimation and thus requires large sample size to ensure sufficient representation across outcome categories [39].
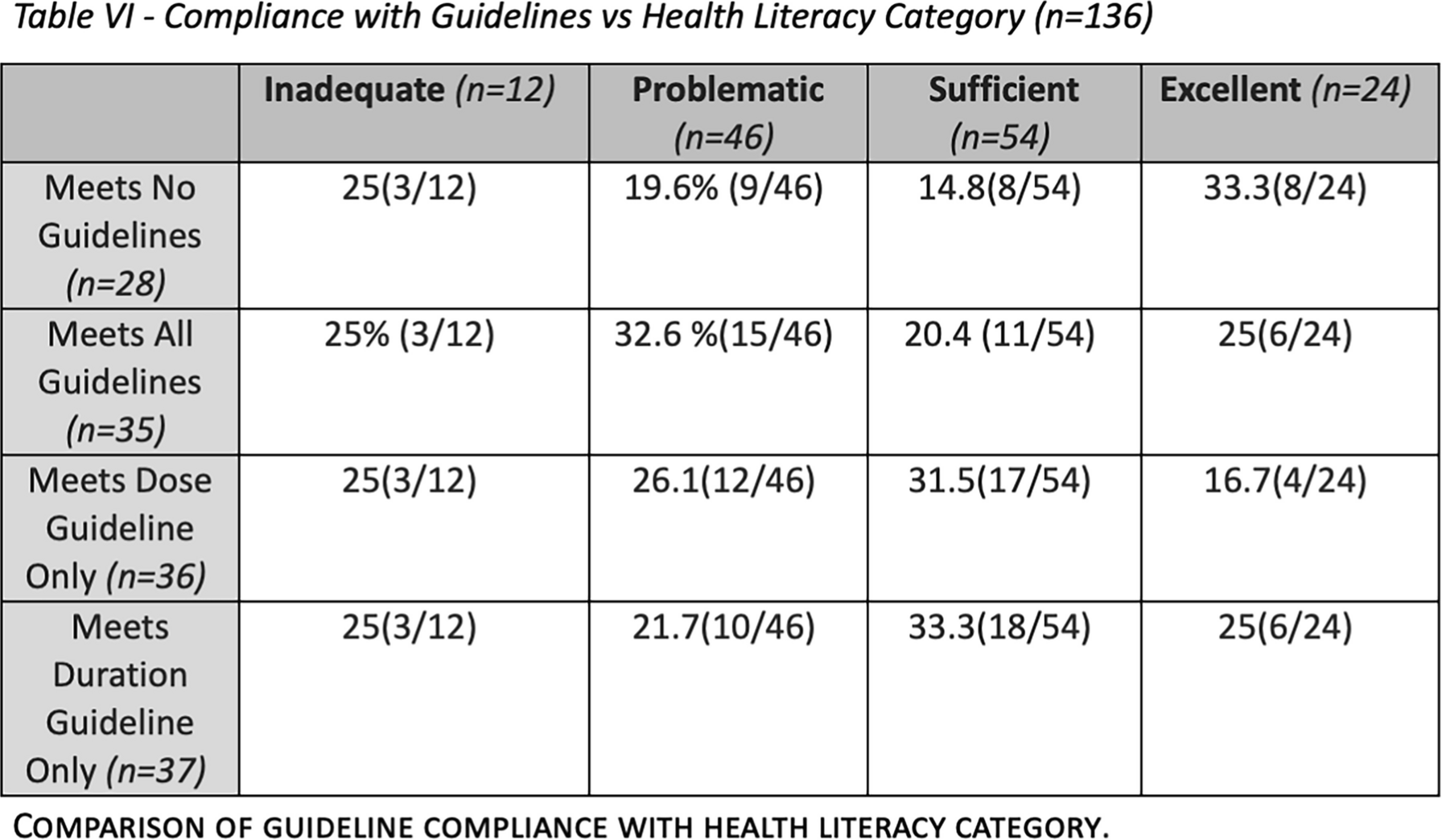
RQ6What metrics were used to evaluate performance of the identified AI tools?
The aim of this research question is to offer an overview of the metrics used to evaluate the performance of the algorithms extracted from the 10 selected articles. The second column of Fig. 11 lists the metrics associated with the respective studies. The most commonly employed metrics include the following:
Fig. 11
Schematic representation of the results of the 10 most cited papers’ analysis. The first column presents the papers’ titles, the second the metrics employed to evaluate the models’ performances and the third summarises the challenges addressed by the studies
Accuracy:
Accuracy measures the predictive ability of a classification algorithm on the testing data, independent of decision biases or prior probabilities, thus allowing the performance of multiple systems to be compared on a common, interpretable scale. Valid and precise assessments of intrinsic accuracy enable users to determine the reliability of diagnostic tools. [40, 41]
Area Under the Curve (AUC):
AUC evaluates a classification algorithm’s ability to produce probability estimates rather than solely class predictions. Thus, this metric is more sensitive than accuracy because it is independent of decision thresholds and class distributions. AUC has therefore been shown to be a superior discriminative indicator in numerous applications and statistical tests [42].
Sensitivity:
Sensitivity, also known as the true positive rate, represents the probability of obtaining a positive result among individuals who actually have the target condition. It reflects the ability of a test to detect true positives (e.g., diseased individuals) [43, 44].
Specificity:
Specificity, also known as the true negative rate, represents the probability of obtaining a negative result among individuals who do not have the target condition. It indicates the ability of a test to detect true negatives (e.g., healthy subjects) [43, 44].
Positive predictive value (PPV):
PPV represents the likelihood that a positive test result corresponds to the target condition. Furthermore, by indicating the portion of true positives among positive results, it helps assess a test’s comparability to the ‘gold standard’ [43, 44].
The metrics described above are those utilised in the 10 articles extracted that underwent in-depth analysis. Consequently, it is possible that other metrics may be used in additional studies within the database, depending on the context and objectives of the research.
RQ7What challenges have been addressed in the development and implementation of AI-driven diagnostic methods?
The integration of AI in the medical field has challenged the traditional approaches to patient care, encompassing diagnosis, treatment and management of pathologies. However, the advent of personalized care has encountered obstacles, including ethical concerns, technical challenges, privacy-related issues, and acceptance by patients and healthcare professionals. To emphasize the importance of the challenges associated with implementing AI-driven diagnostic tools, we analysed the 10 most cited articles from the identified database. These articles were examined to determine how they address specific challenges in the context of AI applications to neurological and mental disorders. In the third column of Fig. 11, the challenges discussed in these articles are summarised in relation to the specific goals and context of each document. Detailed descriptions of the articles are given below:
Acharya et Al. [45] tackles the challenge of diagnosing depression, a condition that often goes undetected despite the availability of effective treatments. The article presents a self-learning model that can detect distinctive features in EEG data. The model was trained and tested on a self-made dataset made by EEG data collected from 15 healthy individuals and 15 depressed patients. The sampling rate of the signals was 256 Hz with a notch filter of 50 Hz to eliminate power line interference. The final dataset had 4348 records divided in half across the two populations of subjects. By creating a new dataset ad hoc for this task, the authors guaranteed a high level of data quality and heterogeneity. Subtle differences in brain activity between depressed and non-depressed individuals are identified through EEG analysis. In particular, EEG signals from the right hemisphere are more distinctive for diagnosing depression. This approach offers a clear advantage in terms of efficiency and improves sensitivity, specificity and accuracy of the diagnosis.
Kessler et Al. [46] explores a new approach to assess suicide risk among US Army soldiers within 12 months following treatment for a psychiatric disorder. The study addresses the challenge of accurately predicting suicide risk, a task that remains difficult despite known risk factors. The authors aim to overcome this limitation by developing a more effective and reliable risk prediction algorithm. To train and test it, the authors built their dataset starting from the Historical Administrative Data System of the Army Study to Assess Risk and Resilience in Servicemembers. This dataset had missing values, and it was inconsistent in some components probably because it wasn’t created for research purposes. To ensure the reliability of the outputs, the remaining missing values were resolved using randomly selected multiple imputations and the inconsistencies were fixed with rational imputations.
Zeng et Al. [47] focuses on overcoming the limitations of traditional psychiatric diagnoses, particularly for Major Depressive Disorder (MDD), which often rely on self-reported symptoms and clinical observations that are susceptible to bias. The authors develop an unsupervised machine learning approach using fMRI scans, enabling classification without pre-labeled data, thus enhancing diagnostic objectivity. To do so, an ad hoc dataset was created, collecting the imaging scans of 24 patients diagnosed with Major Depressive Disorder and 29 healthy subjects. The healthy controls were selected on the basis of demographic similarity to each depressed patient. To avoid biases in the output, all patients underwent MRI under the same conditions and the scans were acquired and processed in the same manner. This research supports the application of machine learning in clinical practice, specifically reducing diagnostic bias and improving clinical outcomes.
In Bone et Al. [48] the objective is to create new diagnostic tools for Autism Spectrum Disorder (ASD) using ML techniques. The research aims to improve the performance of caregiver-report instruments to achieve the “gold-standard” diagnosis. The study seeks to develop robust ML algorithms that achieve efficiently event with datasets containing conflicting data, thereby contributing to more accurate and efficient diagnostic assessments for ASD. The dataset involved in the experiment included ADI-R and SRS scores for 1,264 verbal individuals with ASD and 462 with non-ASD developmental or psychiatric disorders and the subjects’ data were drawn from an IRB approved repository.
Kartsoft et Al. [49] addresses the challenge of personalising PTSD diagnosis using ML techniques to analyse various combinations of predictive features. Unlike previous studies that focused on predictive factors in large groups, this research prioritises less obvious and less frequently recorded variables. The authors apply ML to a large dataset, utilizing support vector machines (SVM) to predict persistent PTSD symptoms. The dataset was made of data collected for the Jerusalem Trauma Outreach and Prevention Study. To predict PTSD symptoms trajectories, features about event characteristics, emergency department records and early symptoms were collected for 957 trauma survivors. This study aims to enhance the accuracy and personalization of PTSD risk prediction.
Gautam et Al. [50] aims to fill a gap in the existing literature by examining the use of DL techniques for the early diagnosis of neurological and psychiatric disorders, including cerebrovascular disease, Alzheimer’s, Parkinson’s, epilepsy, cerebral palsy, multiple sclerosis, autism and migraine. Given the complexity and severity of these diseases, which are often chronic and have poor prognosis, timely and accurate diagnosis is crucial. The article introduces various DL techniques and presents the major neurological disorders, analyzing the publication trends related to these conditions.
Galatzer-Levy et Al. [51] explores the use of advanced computational approaches to develop predictive models capable of classifying individuals with heterogeneous risk factors. In particular, they used the data collected by Shalev et al. (2008) [52] and Videlock et al. (2008) [53], two parts of a longitudinal study that, using classical GLM statistics, previously failed to show a group-wide association between endocrine markers at hospitalisation time and PTSD status 5 months later. The data included assessment of trauma exposure, personal information, neuroendocrine and psychiatric assessments of 152 patients. Notably, the neuroendocrine response, specifically cortisol, emergers as a stable predictor of the development of post-traumatic stress disorder (PTSD) when combined with other clinical data. The article emphasises early prediction and risk factor identification, suggesting that manipulating the mechanisms underlying the development of disorders can help prevent their onset.
Amoroso et Al. [54] propose a novel strategy for early diagnosis of Parkinson’s disease (PD) prior to the manifestation of motor symptoms combining neural network and clinical features. The diagnostic tool is based exclusively on markers derived from MRI and uses an unsupervised methodology to model brain activity in both healthy subjects and patients to explore the brain areas most affected by the disease. To do so, the authors relied on data from the Parkinson’s progressive markers initiative, both for clinical and imaging data. This online repository is strongly research oriented and very reliable. However, they do not specify the solutions adopted in the case of empty cells or inconsistent measurements. The author’s approach focuses on the identification of a combination of different markers, enabling accurate early diagnosis and monitoring of disease progression.
Zhang et Al. [20] aims to identify existing subtypes of psychiatric disorders, such as post-traumatic stress disorder (PTSD) and major depressive disorder (MDD). The identification of these subtypes is conducted through an approach based on functional connectivity patterns, detected via resting-state EEG, and the application of machine learning techniques to identify solutions for connectivity-based diagnosis. To ensure output reliability, the data used to train and test the algorithms were collected specifically for this experiment.
In Eyigoz et Al. [55] aims to predict the future onset of Alzheimer’s disease in cognitively normal subjects through automated linguistic analysis. The study used linguistic data to create predictive models and analyse the correlation between lower early-life linguistic performance and higher incidence of cognitive decline. The experiment relied on data collected by the Framingham heart study, a longitudinal study that tests cognitive status and its decline since 1975. Also in this case, the data source is reliable, but the authors did not reveal how they targeted inconsistent measurements. It emerges that language performance can reveal early signs of cognitive decline and thus be used as markers to identify at-risk individuals, enabling timely interventions.
Comments (0)