Meng X, Yan X, Zhang K, et al. The application of large language models in medicine: a scoping review. iScience. 2024;27(5):109713.
Article
Google Scholar
Shool S, Adimi S, Saboori Amleshi R, Bitaraf E, Golpira R, Tara M. A systematic review of large language model (LLM) evaluations in clinical medicine. BMC Med Inform Decis Mak. 2025;25(1):117.
Article
Google Scholar
Yu E, Chu X, Zhang W, et al. Large language models in medicine: applications, challenges, and future directions. Int J Med Sci. 2025;22(11):2792–801.
Article
Google Scholar
Jung KH. Large language models in medicine: clinical applications, technical challenges, and ethical considerations. Healthc Inform Res. 2025;31(2):114–24.
Article
Google Scholar
Maity S, Saikia MJ. Large Language Models in Healthcare and Medical Applications: A Review. Bioengineering. 2025. https://doi.org/10.3390/bioengineering12060631.
Article
Google Scholar
Singhal K, Tu T, Gottweis J, et al. Toward expert-level medical question answering with large language models. Nat Med. 2025;31(3):943–50.
Article
Google Scholar
Noda R, Tanabe K, Ichikawa D, Shibagaki Y. GPT-4’s performance in supporting physician decision-making in nephrology multiple-choice questions. Sci Rep. 2025;15(1):15439.
Article
Google Scholar
Miranda J, Pereira-Silva R, Guichard J, Meneses J, Carreira AN, Seixas D. Artificial intelligence outperforms physicians in general medical knowledge, except in the paediatrics domain: a cross-sectional study. Bioengineering. 2025. https://doi.org/10.3390/bioengineering12060653.
Article
Google Scholar
Abrantes J. Assessing large language models for medical question answering in Portuguese: open-source versus closed-source approaches. Cureus. 2025;17(5):e84165.
Google Scholar
Riina N, Patlolla L, Hernandez Joya C, Bautista R, Olivar-Villanueva M, Kumar A. An evaluation of English to Spanish medical translation by large language models. 2024 September; Chicago, USA: Association for Machine Translation in the Americas; 2024. p. 222–36.
GBD 2021 Demographics Collaborators. Global age-sex-specific mortality, life expectancy, and population estimates in 204 countries and territories and 811 subnational locations, 1950–2021, and the impact of the COVID-19 pandemic: a comprehensive demographic analysis for the Global Burden of Disease Study 2021. Lancet 2024.
GBD 2021 Diseases and Injuries Collaborators. Global incidence, prevalence, years lived with disability (YLDs), disability-adjusted life-years (DALYs), and healthy life expectancy (HALE) for 371 diseases and injuries in 204 countries and territories and 811 subnational locations, 1990–2021: a systematic analysis for the Global Burden of Disease Study 2021. The Lancet.
Sellergren A, Kazemzadeh S, Jaroensri T, et al. Medgemma technical report. arXiv preprint arXiv:250705201 2025.
D'addario AMV. HealthQA-BR: A System-Wide Benchmark Reveals Critical Knowledge Gaps in Large Language Models. arXiv preprint arXiv:250621578 2025.
Olatunji T, Nimo C, Owodunni A, et al. AfriMed-QA: a Pan-African, multi-specialty, medical question-answering benchmark dataset. arXiv preprint arXiv:241115640 2024.
CONAREME Consejo Nacional de Residentado Medico [Internet]. [cited 6 September 2025]. URL: https://www.conareme.org.pe/web/.
Scraping PDF documents containing exams with highlighted correct answers [Internet]. [cited 6 September 2025]. URL: https://medium.com/gitconnected/scraping-pdf-documents-containing-exams-with-highlighted-correct-answers-68d0a6e9b397.
Hendrycks D, Burns C, Basart S, et al. Measuring massive multitask language understanding. arXiv preprint arXiv:200903300 2020.
Google-Health/medgemma [Internet]. [cited 6 September 2025]. URL: https://github.com/google-health/medgemma/blob/main/notebooks/fine_tune_with_hugging_face.ipynb.
Chung HW, Hou L, Longpre S, et al. Scaling instruction-finetuned language models. J Mach Learn Res. 2024;25(70):1–53.
Google Scholar
Ossowski T, Zhang S, Liu Q, et al. OctoMed: Data recipes for state-of-the-art multimodal medical reasoning. arXiv preprint arXiv:251123269 2025.
Kim H, Hwang H, Lee J, et al. Small language models learn enhanced reasoning skills from medical textbooks. NPJ Digit Med. 2025;8(1):240.
Article
Google Scholar
Arora RK, Wei J, Hicks RS, et al. Healthbench: Evaluating large language models towards improved human health. arXiv preprint arXiv:250508775 2025.
Carrillo-Larco RM, Guzman-Vilca WC, Leon-Velarde F, et al. Peru - Progress in health and sciences in 200 years of independence. Lancet Reg Health Am. 2022;7:100148.
Google Scholar





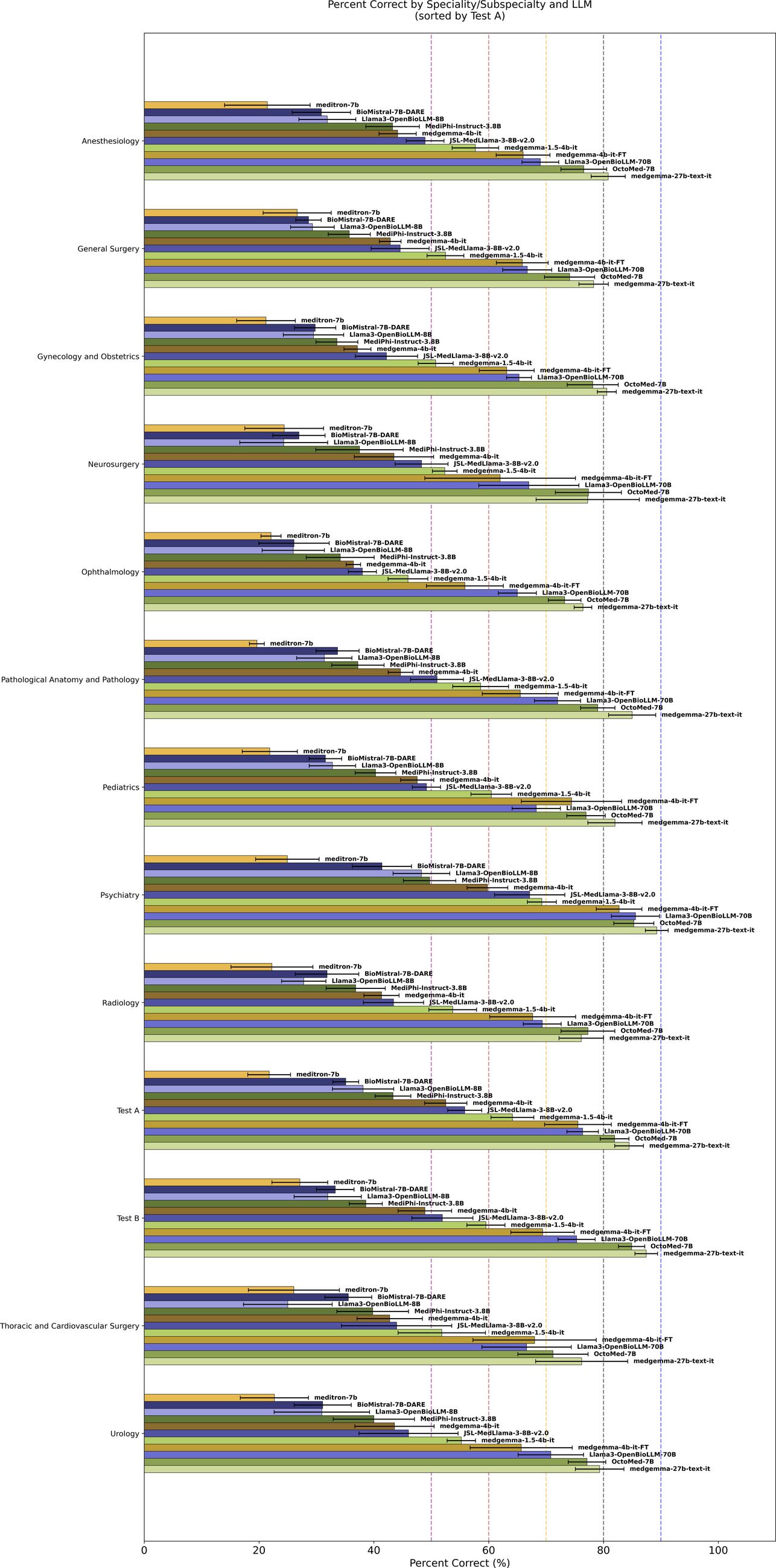
Comments (0)