
Remember me




The following subsections describe the specific noise modeling and k-space sampling assumptions we make for our investigation, as well as the methods we use to optimize k-space coverage and nonuniform averaging patterns.
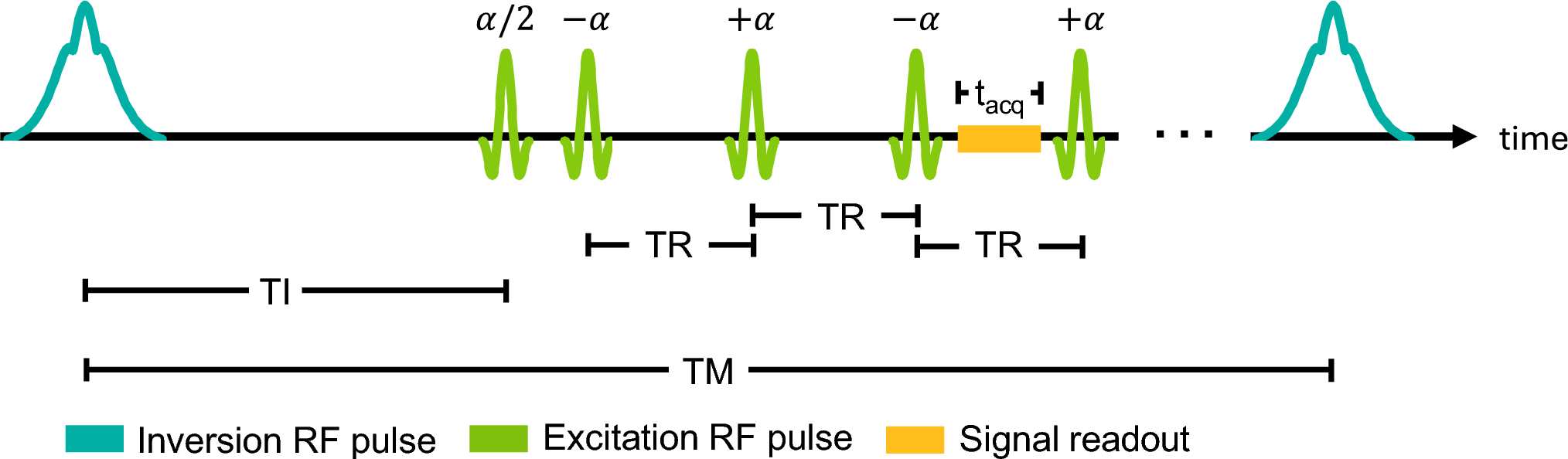
Noise modeling assumptionsFor concreteness and without loss of generality, we consider an acquisition based on 2D Cartesian k-space sampling with one phase-encoding dimension and one readout dimension, with a single readout acquired per TR. Notably, this choice does not limit the relevance of our results, since the mathematical relationship between spatial resolution and noise in Cartesian MRI transcends these sequence-specific assumptions [1, 6]. As a result, even though the underlying mechanisms of noise behavior may vary, mathematically equivalent resolution/noise tradeoffs would also be observed in other 2D Cartesian settings. For example, under the physical modeling assumptions described in the sequel, our simulations would be largely identical if we instead considered data acquired with two phase-encoding directions, as frequently encountered in slice-by-slice reconstruction of 3D Cartesian imaging data (after transforming the fully-sampled readout), or if we considered acquisitions that collect multiple readout lines per TR.
We consider an MRI experiment that acquires noisy k-space measurements on a centered Nyquist-rate Cartesian grid of k-space locations. For simplicity, we assume a square \(N \times N\) sampling grid with even N, although our basic approach is easily generalized to arbitrary rectangular grids. We further assume that data is measured from an array of L receiver coils. This allows us to represent the noisy data using the model:
$$\begin d_ = s_\ell [m,n] + z_, \end$$
(1)
for \(m = -N/2,\ldots , N/2-1\), \(n = -N/2,\ldots ,N/2-1\), and \(\ell =1,\ldots ,L\). In this expression, \(s_\ell [m,n]\) is the ideal (noiseless) k-space sample corresponding to the \(\ell \)th channel, mth phase-encoding position, and nth readout position, and \(z_\) represents the corresponding measurement noise.
Following standard practice in multichannel MRI noise modeling, we model every noise sample as complex-valued zero-mean circular Gaussian random noise [35,36,37]. We also assume that the noise in the multichannel data has been prewhitened [36], such that every noise sample is independent and identically distributed (i.i.d.), with no interchannel correlation. We use \(\sigma ^2\) to denote the common variance shared by each individual noise sample. We also consider the scenario where the acquisition is able to acquire each phase-encoding line multiple times for the sake of SNR improvement through data averaging, and use \(\tilde_m\) to represent the integer number of measurements (averages) for the mth line. After averaging, the noise \(z_\) will be complex-valued zero-mean circular Gaussian with (potentially m-dependent) variance \(\sigma ^2/\tilde_m\).
k-space sampling assumptionsAs already mentioned, we focus on two potential manipulations of data acquisition, one involving reduced k-space coverage with uniform averaging (i.e., \(\tilde_m\) is the same for all m) and the other involving reduced k-space coverage with potentially non-uniform averaging (i.e., \(\tilde_m\) can be independently adjusted for each phase-encoding line). The former option is simpler and generally available by default on most MRI scanners (no pulse sequence programming required), while the latter option is more flexible and can yield higher SNR-efficiency [5, 8,9,10,11,12,13,14, 17] but generally requires pulse sequence modifications to enable full control over the nonuniform averaging pattern.
In both cases, we treat the acquisition gridsize N as an optimization variable that we use to manipulate k-space coverage, with smaller N resulting in lower spatial resolution. We also assume that we are given some upper limit \(N_0\), representing a practical limit on the nominal spatial resolution of the acquisition such that \(N \le N_0\). Notably, even without additional modifications to the acquisition, smaller values of N are naturally associated with higher SNR [1]. However, reducing N without making other sequence changes can make comparisons difficult, since changing N will also impact important experimental factors such as the total experiment duration and the duration of the readout. To ensure fairness and avoid such confounds, it is common in the literature on SNR efficiency (e.g., [4, 6]) to fix both the total experiment duration and the duration of the readout, and we adopt the same approach herein. This isolates the effects of altering the k-space coverage and averaging strategy from other experimental considerations, enabling well-controlled comparisons.
For convenience, we will describe the assumptions we make about modified k-space sampling patterns with reference to a hypothetical maximum-resolution MRI experiment that acquires data on an \(N_0\times N_0\) sampling grid with uniform averaging (i.e., \(\tilde_m = \tilde_0\) for all m, for some integer \(\tilde_0\)). The total acquisition time of this hypothetical experiment will be proportional to \(\tilde_0 N_0\), the total number of TRs needed to measure each of the \(N_0\) phase-encoding positions \(\tilde_0\) times. Since uniform averaging is a special case of non-uniform averaging, our description below will focus on the non-uniform case.
Holding the total experiment duration constant means that if we reduce the value of N below \(N_0\), we must correspondingly change the number of averages \(\tilde_m\) for each phase-encoding location such that the total number of TRs remains constant. Intuitively speaking, if we have fewer phase-encoding positions to measure, we will then have additional time that can be spent on increased averaging of the remaining phase-encoding positions. Mathematically, this corresponds to the constraint that
$$\begin \sum _^ \tilde_m = \tilde_0 N_0. \end$$
(2)
In addition, maintaining the readout duration when the number of readout samples N is reduced below \(N_0\) often involves changes to the readout gradient amplitude and the acquisition bandwidth. These changes are beneficial since they lead to SNR-improvements akin to averaging [6]. Specifically, if the variance of the unaveraged noise had originally been \(\sigma ^2\) for the hypothetical high-resolution reference experiment, then after making appropriate bandwidth adjustments to accommodate N readout samples with the same readout duration, the variance of the averaged noise \(z_\) in the modified acquisition will become \(\sigma ^2/(\tilde_m N_0/N)\).
For notational simplicity, we define an “effective" number of averages \(w_m\) to combine the effects of phase-encode averaging and readout bandwidth adjustments, with \(w_m = \tilde_m N_0/N\). With this choice, the noisy averaged data samples \(d_\) can still be modeled as in Eq. (1), except that the variance of \(z_\) is now given by \(\sigma ^2/w_\). The previous constraint on the total scan time from Eq. (2) can also be rewritten in terms of the effective number of averages as
$$\begin \sum _^ w_m = \tilde_0 N_0^2/N. \end$$
(3)
k-space sampling optimizationWe formulate our sampling optimization problem in a generic way that is compatible with arbitrary image reconstruction techniques, with optimization performed with respect to a database of high-quality training data. Specifically, we perform optimization of both the k-space acquisition (i.e., the gridsize and effective number of averages) and the reconstruction parameters using a loss function that quantifies the average difference between the denoised/reconstructed image and the corresponding reference image across the training set. Note that the implementation used in this paper does not attempt to model aspects of acquisition physics that may influence image contrast or structure (e.g., the effects of relaxation or off-resonance). This can be viewed as implicitly assuming either that such effects are negligible or that the relevant sequence parameters are held fixed. In addition, we intentionally approach denoising from a reconstruction perspective rather than an image post-processing perspective. Reconstruction-based denoising approaches have a long precedent (e.g., our own previous work [15,16,17,18]), and generally exhibit improved performance because the raw complex-valued multichannel k-space data possesses more information than a reconstructed coil-combined image [38].
To enable easy quantitative performance comparisons between images produced from different acquisition gridsizes N, we assume that images are consistently reconstructed on an \(N_0\times N_0\) grid regardless of the value of N. Specifically, we assume a generic reconstruction function of the form
$$\begin \hat} = g_,N,\textbf}( \textbf), \end$$
(4)
where \(\hat} \in \mathbb ^\) is the \(N_0 \times N_0\) reconstructed image, \(\textbf \in \mathbb ^\) is the vector of averaged data samples \(d_\), \(\textbf \in \mathbb ^N\) is the vector of the effective number of averages \(w_m\) for each phase-encoding position, and \(\textbf\) is the vector of trainable parameters of the reconstruction method (e.g., the regularization parameter for SENSE-TV reconstruction, apodization weights for simple linear filtering, or neural network weights for U-Net reconstruction).
For training, we assume access to a set of T “noise-free" high-resolution k-space datasets \(\textbf_t \in \mathbb ^\) for \(t=1,\ldots ,T\). The entries of each \(\textbf_t\) vector correspond to dataset-specific instances of the ideal samples \(s_\ell [m,n]\) from Eq. (1) over an \(N_0 \times N_0\) grid. For each candidate acquisition gridsize N, we extract a lower-resolution version \(\textbf_t^N \in \mathbb ^\) by discarding samples that would fall outside an \(N\times N\) grid. We also form a corresponding low-resolution “noise-free" reference image \(\textbf_t^N \in \mathbb ^\) by zero-padding \(\textbf_t^N\) to an \(N_0\times N_0\) grid, applying an inverse Fourier transform, and combining channels using known coil sensitivity maps [39]. Our decision to use low-resolution reference images instead of high-resolution reference images was based on the behavior we observed for U-Net reconstruction, whose performance degraded if high-resolution reference images were used for training. We specifically observed substantial hallucination of high-frequency content in this scenario—likely because this setup resembles a super-resolution task, which is often substantially more difficult than denoising [2].Footnote 1
To obtain realistic simulations of noisy measurements that are consistent with our noise model (i.e., Eq. (1) with the updated variance described in Sect. 2.1.2), we start by generating pseudo-random noise vectors \(\textbf_t^N \in \mathbb ^\) with zero-mean i.i.d. circular complex Gaussian entries of variance \(\sigma ^2\). For a given N and \(\textbf\), this allows us to produce simulated noisy data with realistic noise statistics using;
$$\begin \textbf_t^N = \textbf_t^N + \frac}} \odot \textbf_t^N, \end$$
(5)
where \(\odot \) represents elementwise multiplication, and through a slight abuse of notation, \(\frac}}\) represents the length-\(N^2 L\) vector obtained by setting all of the entries corresponding to the mth phase-encoding position (across all readout points and channels) equal to \(1/\sqrt\).
Based on this setup, we formulate the following constrained optimization problem to jointly optimize the acquisition parameters N and \(\textbf\) and reconstruction parameters \(\textbf\):
$$\begin \begin \hat&= \arg \min _ \sum _^T J\left( g_}(N),N,\hat}(N)}\left( \textbf_t^N+ \frac}(N)}} \odot \textbf_t^N\right) , \textbf_t^ \right) \end \end$$
(6)
subject to
$$\begin&\}(N), \hat}(N)\} = \arg \min _,\textbf} \sum _^T J\left( g_,N,\textbf}\left( \textbf^N_t+ \frac}} \odot \textbf_t^N\right) , \textbf^N_t \right) \nonumber \\&\text \Vert \textbf\Vert _1 = \tilde_0 N_0^2/N. \end$$
(7)
In this expression, \(J(\textbf,\textbf)\) is a distance metric to quantify the discrepancy between the reconstructed image and the reference image. Note that we have adopted a two-level optimization structure in which the reconstruction parameters \(\hat}(N)\) and the averaging pattern \(\hat}(N)\) is optimized with respect to low-resolution reference images for each N, while N is chosen with comparison against the high-resolution reference image. This structure ensures that \(\hat}(N)\) and \(\hat}(N)\) are obtained from solving a pure denoising problem, while still ultimately prioritizing high-resolution results when selecting N.
For optimization, we treat the reconstruction parameters \(\textbf\) as continuous variables that can be optimized using standard techniques. For \(\textbf\), the true number of averages must ultimately be integer-valued. While it is common in the literature on sampling design for undersampled MRI to employ advanced algorithms that directly enforce this constraint [20,21,22,23,24,25,26,27,28,29,30], such methods introduce complexity that is unnecessary for our purposes. Instead, following classical practice in statistical experiment design [41, 42] and prior MRI literature on optimal averaging [8, 9], we relax the integer constraint and allow the entries of \(\textbf\) to take arbitrary positive real values. This relaxation enables the use of standard optimization techniques such as stochastic gradient descent and can sometimes even accommodate analytic solutions (see, e.g., [17, Thm. 3.1] and related discussion), which is especially advantageous given that integer programming is generally NP-hard. Importantly, this approach—sometimes known as “continuous design," “approximate design," or “design for infinite sample size" [41, 42]—produces continuous solutions. These solutions can be converted into valid integer-valued solutions through an appropriate rounding procedure, without requiring that the desired total number of measurements \(\tilde_0N_0\) is fixed in advance. Note that our implementation did not explicitly prohibit elements of \(\textbf\) from going to zero, which would result in undersampling—however, undersampled patterns did not emerge in the experiments in this paper.
The parameter N should also be integer-valued, but unlike \(\textbf\), a continuous relaxation is not straightforward or particularly useful in this case. In this work, we use a brute-force grid search over the finite set of candidate N values. Brute-force search is a classical and widely used approach in discrete optimization—it is simple to implement, helps avoid certain types of local minima, and can be very efficient when the search space is small.
Taken together, this results in two different algorithms, depending on whether we assume uniform averaging or allow nonuniform averaging. The algorithm for uniform averaging is:
For each candidate value of N:
Obtain \(\hat}(N)\) by setting \(\hat_m(N) = \tilde_0 N_0^2/N^2\) for all m. (The averaging pattern is constant, and will not be treated as an optimization variable)
Iteratively optimize the reconstruction parameters \(\hat}(N)\) by solving Eq. (7) with fixed \(\hat}(N)\), using standard continuous optimization techniques (in this work, we use either stochastic gradient descent or the Adam optimizer, as described in the sequel).
Return the \(\hat\), \(\hat}(N)\), and \(\hat}(N)\) values that achieved the lowest value of the loss function from Eq. (6).
The algorithm for nonuniform averaging is:
For each candidate value of N:
Initialize \(\hat}(N)\) by setting \(\hat_m(N) = \tilde_0 N_0^2/N^2\) for all m.
Solve Eq. (7) to obtain \(\hat}(N)\) and \(\hat}(N)\) using standard continuous optimization techniques as above. We use projected stochastic gradient descent to enforce the constraints on \(\textbf\). The optimal projection onto the constraint set can be derived using simple Lagrange multiplier methods, and is achieved by replacing each \(w_m\) with \(w_m+ \beta /N\), with \(\beta = \tilde_0 N_0^2/N - \sum _^ w_m\).
Return the \(\hat\), \(\hat}(N)\), and \(\hat}(N)\) values that achieved the lowest value of the loss function from Eq. (6).
After obtaining a continuous averaging design in terms of effective averages \(\hat}\), we convert back to actual averages and round to integer values using a simple (potentially suboptimal) rounding procedure. Specifically, the final integer-valued averaging pattern is obtained by solving
$$\begin \hat} = \arg \min _ \in \mathbb ^N} \Vert \textbf - N/N_0\hat}\Vert _1 \text \Vert \textbf\Vert _1 = \tilde_0 N_0 \end$$
(8)
An optimal solution to this problem can be obtained by first rounding each entry of \(N/N_0\hat}\) to the nearest integer, i.e., \(\hat} = \textrm(N/N_0\hat})\). If the resulting pattern \(\hat}\) sums to \(\tilde_0 N_0\), the process terminates because the rounded solution is optimal with respect to Eq. (8). Otherwise, if \(\hat}\) includes too many or too few averages, we iteratively subtract or add one average at a time in a greedy manner until the sum constraint is satisfied. At each step, one average is added or removed from the phase-encoding position that will result in the smallest increase of the cost function Eq. (8). In case of ties, averages nearest to the center of k-space are preferentially preserved. It can be shown, using the separability and piecewise-linearity properties of the \(\ell _1\)-norm and absolute value, that this greedy algorithm will produce a globally optimal solution to Eq. (8).
MethodsDataOur experiments are based on real T1-weighted brain MRI data from fastMRI [33]. Specifically, we used the central 8 slices of multichannel k-space data from 373 subjects (2984 slices in total) that were initially provided with a 640 \(\times \) 320 acquisition matrix. However, as is common in the raw k-space data produced by certain scanners, these datasets represent an intermediate step in the conventional oversampled analog-to-digital conversion process [43, Ch. 4.8.1] (after analog anti-aliasing but before completion of digital anti-aliasing), with unresolved \(2\times \) readout oversampling. This produces data with temporally-correlated k-space noise (non-white spectral characteristics). As a result, to ensure that our i.i.d. noise modeling assumptions would be valid, we finished the analog-to-digital conversion process by applying the remaining standard low-pass filtering and downsampling steps as described in [43, Ch. 4.8.1]. After processing, each k-space dataset had an acquisition matrix size of \(N_0\times N_0 = 320\times 320\) (corresponding to a 220 mm \(\times \) 220 mm FOV with 5 mm slice thickness), with \(L=16\) channels.
Notably, since these are real datasets, they are not truly “noise-free", even though we will use them as the “noise-free" high-resolution k-space datasets \(\textbf_t\) in our formulation. This is a potential concern, since it has been previously shown that the presence of “hidden noise" in data that is assumed to be noise-free can sometimes cause interpretation problems [44]. However, we do not expect this to be a major confound for this study, since our simulated noise is substantially larger than the “hidden noise" present in the data, and because we are also using sensitivity-based coil combination to generate reference images, which can help mitigate the effects of hidden noise [44].
To facilitate later numerical optimization steps, each slice was independently normalized by dividing all its multichannel k-space samples by its corresponding maximum voxel magnitude across all channels—this ensures that the complex-valued multichannel images will each have voxel magnitudes in the range of [0, 1]. The 2984 slices were partitioned into three sets: 2648 for training, 168 for validation (used for choosing parameters such as network architectures, learning rates, and number of training epochs), and 168 for testing. Sensitivity maps for the SENSE model were obtained using PISCO [45].
Fig. 1
Illustrative examples of the different SNRs we considered, shown for a representative slice. The top row shows the ground truth image \(\textbf_t^\), as well as simulated noisy images that are obtained for high-resolution (\(N_0\times N_0\)) sampling with uniform averaging \(\tilde_0 = 8\) for different simulated noise levels. The images were obtained using simple inverse Fourier transform reconstruction of the averaged noisy data, followed by SENSE-based coil combination. We show normalized root-mean-squared error (NRMSE) and structural similarity (SSIM) metrics in the top left corner of each noisy image. The bottom two rows show zoom-ins to specific patches, with the patch locations marked in the ground truth image of the top row
Our simulations explored four different noise levels: SNR = 2, 3, 5, and 10, representing denoising problems with varying degrees of difficulty as illustrated in Fig. 1. The target SNR levels were defined for images generated using conventional reconstruction after averaging—i.e., Fourier reconstruction with sensitivity-based coil combination. The simulated noise variance was selected to produce the desired SNR levels in the central white matter of typical brain slices, assuming a high-resolution acquisition (\(N_0=320\)) with uniform 8\(\times \) averaging (i.e., \(\tilde_0 = 8\)).
Fig. 2
Optimized averaging patterns corresponding to SENSE-TV denoising/reconstruction, obtained using (top row) uniform averaging and (bottom row) nonuniform averaging. For reference, the baseline acquisition approach (\(8\times \) averaging of high-resolution \(N_0\times N_0\) data) is shown in the top left
Fig. 3
Optimized averaging patterns corresponding to U-Net denoising/reconstruction, obtained using (top row) uniform averaging and (bottom row) nonuniform averaging. For reference, the baseline acquisition approach (\(8\times \) averaging of high-resolution \(N_0\times N_0\) data) is shown in the top left
Training and evaluationFor each SNR level and each reconstruction method, the k-space sampling patterns and reconstruction parameters were jointly optimized to minimize an objective function in the form of Eq. (6), as already described in Sect. 2.1.3. In all cases, training and parameter tuning were performed using the mean-squared error loss function \(J(\textbf,\textbf) = \Vert \textbf - \textbf\Vert _2^2\). Practical constraints prevent us from comprehensively evaluating other choices of \(J(\cdot ,\cdot )\), although we anecdotally observed that other loss functions such as the \(\ell _1\)-norm or structural similarity (SSIM) [46] produced similar optimized k-space averaging patterns.
Results were evaluated using the 168 datasets that were set aside for testing. Evaluations were based on comparing the denoising results against the corresponding reference images, including qualitative visual assessments as well as quantitative comparisons using common measures such as the normalized root-mean-squared error (NRMSE), defined as \(\Vert \textbf-\textbf\Vert _2/\Vert \textbf\Vert _2\)), and SSIM [46].
Additional reconstruction-specific details are described below:
SENSE-TV Denoising/Reconstruction
In this case, reconstruction was performed using Eq. (4), using the denoising/reconstruction function
$$\begin g_,N,\textbf}( \textbf) = \arg \min _ \in \mathbb ^^2}} \Vert \sqrt} \odot ( \textbf \textbf - \textbf) \Vert _2^2 + \lambda \Vert \textbf\textbf\Vert _1. \end$$
(9)
Here, \(\textbf\) is the forward model of data acquisition (representing the combined effects of sensitivity encoding by the multichannel receiver array, Fourier encoding, and low-resolution sampling on the \(N\times N\) subset of the nominal \(N_0 \times N_0\) k-space grid), \(\textbf\) is a spatial finite difference operator, \(\lambda \) is the TV regularization parameter, and \(\sqrt}\) appears in the data consistency term to properly model the known statistical characteristics of the averaged data \(\textbf\).
The solution to Eq. (9) was obtained using an ADMM approach [47, Sect. 6.4.1] with the number of iterations fixed at 50. For each noise level and each N, the ADMM penalty parameter—an algorithmic parameter that does not appear in Eq. (9)—was roughly tuned to maximize NRMSE for a representative slice, after which it was held fixed.
The optimizable reconstruction parameters \(\textbf\) consisted solely of the TV regularization parameter \(\lambda \). In the uniform-averaging scenario, \(\textbf\) was optimized using stochastic gradient descent (batch size = 8) with a learning rate of 0.01 and a decay factor of 0.9 per epoch for 10 epochs (further epochs yielded consistent results). In the nonuniform-averaging scenario, \(\textbf\) and \(\textbf\) were jointly optimized using projected stochastic gradient descent (batch size = 8) to enforce the constraints on \(\textbf\). Additionally, at each step, the gradients for \(\textbf\) were normalized to have unit \(\ell _2\)-norm, which we found to be helpful for stabilizing the optimization process across different SNRs and reconstruction methods. During the first 45 epochs, \(\textbf\) and \(\textbf\) were jointly optimized using a learning rate of 0.001 and a decay factor of 0.99 per epoch for \(\textbf\), and a learning rate of 0.01 and a decay factor of 0.99 per epoch for \(\textbf\). Subsequently, the averaging pattern was rounded to integer values and fixed, and \(\textbf\) was further optimized for an additional 5 epochs so it could adapt to the rounded averaging pattern.
U-Net Denoising/Reconstruction
In this case, denoising/reconstruction was performed using the U-Net implementation from Ref. [33], with a base number of 64 channels, 3 pooling layers, and no dropout. The number of input channels was set to 32 (the real and imaginary parts of the images obtained from applying the Fourier transform to the zero-padded k-space data from each of the \(L=16\) channels), and the number of output channels was set to 2 (the real and imaginary parts of the coil-combined image).
In the uniform-averaging scenario, training was performed using a batch size of 8, using the Adam optimizer for the neural network parameters \(\textbf\) with a learning rate of 0.0003 for 100 epochs. In the nonuniform-averaging scenario, \(\textbf\) and \(\textbf\) were optimized jointly (batch size = 8) for 90 epochs. The Adam optimizer with a learning rate of 0.0003 was used for \(\textbf\). Projected stochastic gradient descent for with a learning rate of 0.01 and a decay factor of 0.99 per epoch was used for \(\textbf\), using gradient normalization as described previously. Subsequently, the averaging pattern was rounded to integer values and fixed, and \(\textbf\) was further optimized for an additional 10 epochs.
Fig. 4
Plots of the quantitative performance of SENSE-TV denoising/reconstruction as a function of resolution, shown for different averaging strategies and different SNR levels. Each plot shows the mean NRMSE and SSIM values for the uniform averaging and nonuniform averaging schemes for different spatial resolution choices. The best performances for each approach are marked with circles. The resolution of the acquisition is expressed as a percentage relative to the baseline acquisition, i.e., \(N/N_0 \times 100\%\). For reference, we also plot the line corresponding to the results obtained using the conventional high-resolution (\(N=N_0\)) uniformly averaged baseline, which matches the first point (100% resolution) of the uniform averaging curve. To assist with interpretation, we have chosen to plot 1-NRMSE values (higher is better) in the top row, which is consistent with the SSIM values (where we also have that higher is better) in the bottom row
Fig. 5
Comments (0)