
Remember me
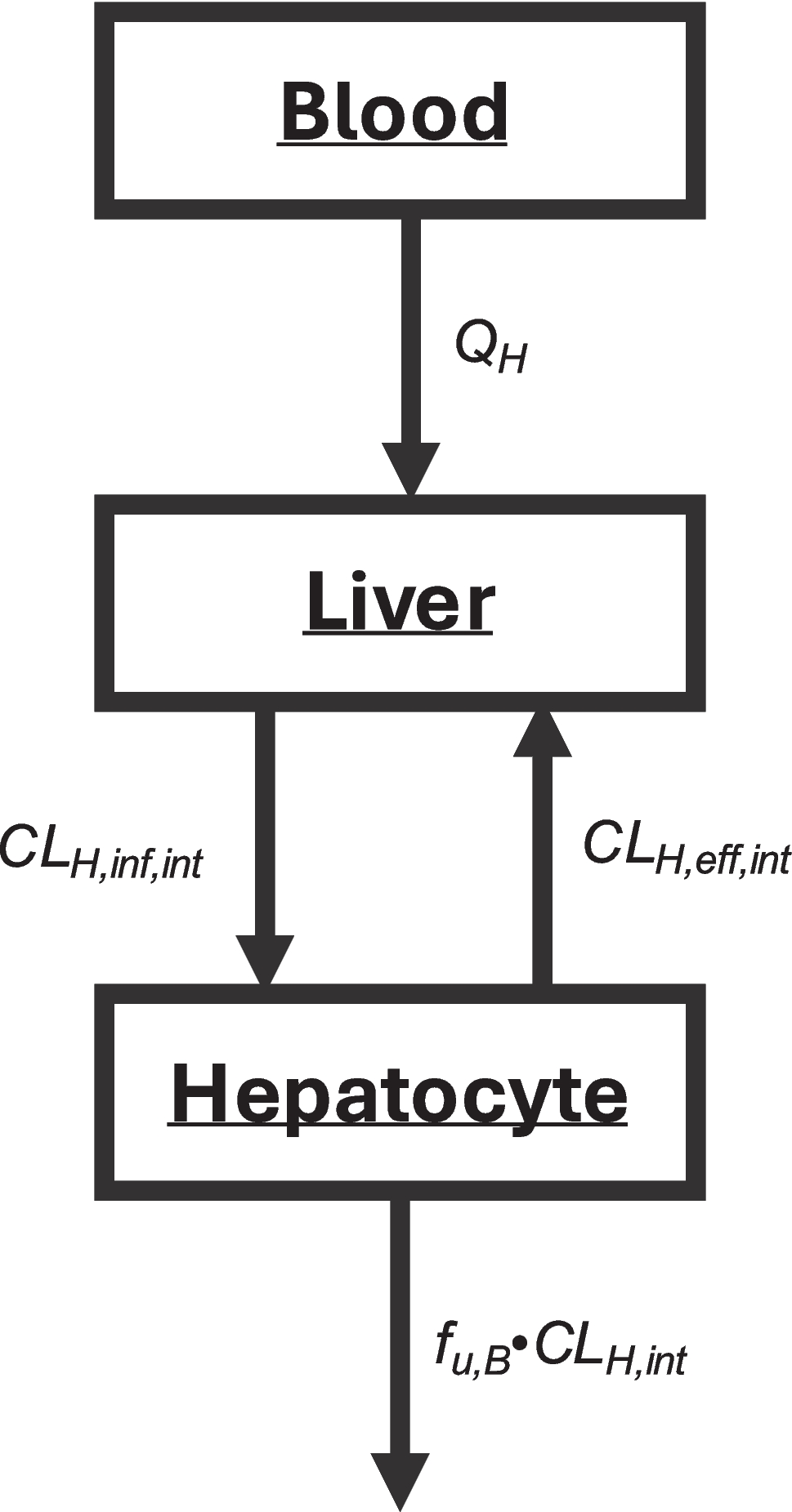

To simulate and estimate the data, NONMEM (ICON plc, Ireland, Version 7.5) as well as PsN (Uppsala University, Sweden, Version 5.3.1) was used. The visualization, calculations and automatization of the workstream was done with R (Version 4.2.0) executed via Visual Studio Code (Version 1.95).
Standard Approach and Randomized-Exposure Mixture-Model Analysis with Type-1 Error ControlStandard ApproachFor the STA, the base model is without drug effect parameter (Eq. 1). The full model on the other hand adds one or multiple parameters describing an E-R relationship (Eq. 2).
$$=\text\left(_},_}\right)$$
(1)
$$y=base\left(\theta_,\eta_\right)\blacksquare\;drug(t,\theta_,\eta_,AUC)$$
(2)
y is the individual prediction, base is a function describing the baseline observation, drug is a function describing the impact of a drug exposure, \(\blacksquare\) represents any arithmetic operation like addition or multiplication, t is time, \(\theta\) are fixed effects while \(\eta\) are random effects of the function, AUC is the exposure metric used (in this study: area under the concentration–time curve (AUC)). When the full model shows a significant decrease of OFV, it is said that a significant exposure–response relationship exists.
Randomized-Exposure Mixture-Model Analysis with Type-1 Error Control (REMIX)Randomized-exposure mixture-model analysis with type-1 error control (REMIX) builds on the IMA method developed for treatment-response analysis. If one would apply the original IMA method in an E-R analysis, the two sub models in the mixture model setting would not differ for the placebo arm. To overcome this issue, in the REMIX approach, randomly assigned exposure values (AUC) are imputed with replacement to the placebo patients from the treatment patients. This can be achieved by either sampling from the AUC distribution directly from the treatment arm, or sampling doses together with the individual PK parameters from the treatment arm. The arm allocation remains unchanged. In the control stream, the two sub models remain the same as for the original IMA method: sub model 1 with a drug effect (Eq. 2) and sub model 2 with a zero-drug effect (Eq. 1). However, here the definition for the base and full model differs from the STA. In REMIX, like IMA (7), the base model is defined as a model where the probability of sub model 1 over sub model 2 in the mixture model is equal for each subject (Eq. 3) whereas, in the full model, the probability is estimated and dependent on the arm assignment (Eq. 4). Note that in case where the treatment and placebo arm are of different size, the equation for the base (Eq. 5) and full (Eq. 6) REMIX models are changed to mimic the saturated IMA structure (8). Although the method evolved from the IMA approach (7) the name REMIX was chosen intentionally to highlight the different aspects of this method (exposure randomization and the use of mixture models) and prevent misinterpretation caused by the “model averaging” part of IMA, which may be misleading as no conventional model averaging is performed in the IMA method.
$$\text\left(1\right)=\text\left(2\right)=0.5$$
(3)
$$\begin\text\left(1\right)=\text\cdot _1}+(1-\text)\cdot (1-_1})& |& \text\left(2\right)=1-\text(1)\end$$
(4)
$$\begin\text\left(1\right)=_1}& |& \text\left(2\right)=1-\text(1)\end$$
(5)
$$\begin\text\left(1\right)=\text\cdot _1}+(1-\text)\cdot _2}& |& \text\left(2\right)=1-\text(1)\end$$
(6)
ARM is either 0 for placebo patients or 1 for treatment patients, \(_\) are the estimated mixture proportion parameter \(\in [\text]\).
Both STA and REMIX methods still compare the benefit of adding one or multiple parameters between base and full model using a likelihood ratio test. However, one noticeable difference between the STA and the REMIX method is that, for STA, the degrees of freedom equal the number of drug effect parameters added, while, for REMIX, the degrees of freedom is always one for the added mixture proportion parameter. Figure 1 shows a graphical comparison of STA and REMIX. Code examples for both methods as well as a depiction of the dataset manipulation are given in the supplemental material (Appendix 1).
Fig. 1
Data analysis workstream for STA and REMIX
Study DesignA simulation study of a hypothetical antidiabetic drug with effect on fasting plasma glucose (FPG) given via infusion was conducted to investigate REMIX. The treatment arm consisted of either two or three dose groups, with a different space between doses (low, medium or high) such that the resulting exposure values did not overlap to ensure a clear differentiation in response across different dose groups. The placebo arm was the same size as the treatment arm. Simulations were performed with varying patient numbers of 3, 10, 30, or 100 patients per dose group and doses in each scenario, yielding a total of 16 combinations (4 different number of patients per dose group × 4 combinations of two doses as low and medium or low and high or medium and high, or three doses). To evaluate the effect of different structural models on the T1 and type II error as well as other model performance aspects, three direct pharmacodynamic (PD) models with linear, loglinear or emax E-R relationships as well as an indirect PD model, a turnover model, with an emax effect on Kout, were tested. Note that different doses were assumed for different structural models to ensure similar drug effect sizes across different E-R relationships. Furthermore, on top of the impact of the drug effect model structure and the sample size, the influence of ill spaced dosing (AUC values partially overlap), uneven treatment to placebo arm sizes (3:1), multiple PD measurements (7), and different residual unexplained variabilities (RUV) on the model performance were investigated in a direct emax drug effect model structure scenario (Table I).
Table I Dosing Schemes as well as PK- and PD- Measurement Schedule for the Different Scenarios TestedSimulation and Estimation WorkstreamThe analysis workstream for the stochastic simulation and estimation (SSE) analysis was the following: Simulation of a new dataset using a PK-PD model utilizing the original dataset was followed by an estimation step in which individual PK parameters are estimated using the same structural PK model as in the simulation step. Then the corresponding AUC values are calculated (Eq. 7) and used for the E-R analysis.
DOSE is the Dose given to an individual in a single dose, while CLi is the individual clearance parameter for the subject i.
For the T1 investigation (no real drug effect simulated) the arm allocation was randomly permutated after the PK analysis and AUC calculation to mimic a structural model misspecification. Then, the AUC values from the treatment arm are sampled with replacement for all subjects respectively. For the power investigation (real drug effect simulated) no arm permutation was performed. The treatment arm remained unchanged, while the placebo patients got randomly sampled AUC values from the treatment patients imputed. Thereafter, STA and REMIX were applied to analyze the data.
Case ExamplesTo further demonstrate the properties of REMIX and its potential application in a drug development setting, two case studies for a hypothetical phase II clinical study were simulated: In the first case study, the placebo-effect model was misspecified, i.e. no placebo-effect parameter in the estimation model, but in the simulation model, and a small drug effect was simulated. In the second case study, the placebo effect was not misspecified, i.e. placebo-effect parameter was present in the simulation and estimation model, and a stronger drug effect was simulated.
The E-R model structure was a turnover model with emax effect on Kout. The exposure metric used was AUC. To make the case study more realistic, the PK parameters as well as covariates were simulated to follow a similar distribution as the one published for empagliflozin (9). The covariates on the CLi parameter (which are used for AUC calculation) were age, body weight at baseline and sex. AUC values were derived by imputing doses and individual clearance values from the treatment arm to the placebo patients. (Table II).
For both case examples, normalized prediction distribution errors (NPDE) as well as visual predictive checks (VPC) were performed and inspected for the base and full REMIX and STA models, respectively as graphical model diagnostics. For the case example without placebo model misspecification and a clear drug effect, a power analysis was performed to assess if REMIX had a detrimental effect on power compared to STA. For 4 to 100 patients (step size: 12 patients) SSEs were performed with the full model as simulation model to investigate the power of STA and REMIX, respectively. Code examples for the R-script used to generate the datasets, the simulation, and the estimation processes are given in the supplemental material (Appendix 3).
Table II Information for the Case ExamplesAnalysis of Type I Error RateTo investigate the T1 inflation, 1000 simulations were conducted following the previously mentioned workstream for the T1 rate. The total number of times the respective full model (STA or REMIX) described the data statistically better (assuming a chi-square distribution with degrees of freedom equal to the number of drug effect parameter for STA and one for REMIX) than the respective base model divided by the total number of simulations and estimations that resulted in a succeeded NONMEM execution (Appendix 2) is the T1 rate (Eq. 8). Following a binomial distribution, the 95% confidence interval (CI) for a 5% T1 rate after 1000 simulations is between 3.81% and 6.53% (Eq. 9). Therefore, every T1 rate above 6.54% will be seen as inflated.
$$1}_}=\frac>\text\right|}}$$
(8)
$$\text=\text\pm _-\frac\cdot \sqrt\cdot \frac}}}$$
(9)
where || counts the scenarios for which the criteria inside are met, δOFV is the difference in OFV between full model and base model, C is the critical value following a chi-square distribution, n is the total number of succeeded runs, CI is the 95% CI, p is the expected proportion of interest (in this analysis always 0.05), \(_-\frac\) is the z-value for the desired level of confidence (in this analysis always 95%).
Analysis of PowerFor power evaluation, 1000 simulation sets, following the workstream with a simulated drug effect present, were generated. The power (or 1—type II error) was defined as the total number of cases where the respective full model outperformed the corresponding base model divided by the total number of simulations with successful estimations (Eq. 10). The power was considered acceptable if it was above 80% in this analysis.
$$\text=\frac>\text\right|}}$$
(10)
Analysis of Predictive PerformanceFor the investigation of the predictive performance, the mean of the relative root mean square error (rRMSE) and its 95% CI as well as the mean of the relative bias (rBias) and its 95% CI of 1000 SSEs were calculated for each base and full model, respectively, to compare the difference between simulated and model-predicted FPG values (Eqs. 11–12). rRMSE values are compared within each setting, where the lower the rRMSE value the better the model description for the individual scenario. For the rBias, the success criterion was defined to be the inclusion of zero in the 95% CI, as this would mean zero bias was included in the 95% CI for the corresponding model prediction.
$$\text=\sqrt\cdot \text}\cdot \sum_=1}^}\sum_=1}^}\frac}_,\text}-}_,\text})}^}}_,\text}}^}} \cdot 100$$
(11)
$$\text=\frac\cdot \text} \cdot \sum_=1}^}\sum_=1}^}\frac}_,\text}-}_,\text}}}_,\text}}\cdot 100$$
(12)
where n is the total number of individuals, m is the total number of observations per individual, predi,j is the prediction for FPG for the ith individual at the jth time point, obsi,j is the observed FPG for the ith individual at the jth time point.
Analysis of Precision and Accuracy of E-R parametersTo investigate the precision and accuracy for the drug effect parameters, 1000 simulations with a true drug effect present were investigated regarding their estimations for the drug-effect parameters for each base and full model, respectively. The mean and 95% CI of the estimated parameters for each different scenario were then compared to the STA full model scenario with 100 patients per dose group and three dose groups for the respective drug-effect structure, as these estimated drug-effect parameters were considered the “true” parameter (Eqs. 13–15). The success criterion was met, if the 95% CI overlapped with the “true” parameter.
$$\overline }=\sum_=1}^}\frac}_}}}$$
(13)
$$\upsigma =\sqrt\cdot \sum_=1}^}_-\overline)}^}$$
(14)
$$CI=\left(\overline-_}\cdot \frac},\overline+_}\cdot \frac}\right)$$
(15)
where \(\overline }\) is the mean of a predicted effect parameter for o simulations for a specific setting, Xk is the estimation for the kth simulation, o is the total number of simulations for each setting, \(\upsigma\) is the standard deviation of a predicted effect parameter for o simulations for a specific setting.
Comments (0)